定制你的 YOLO11 网络架构(下)
前言
在 定制你的 YOLO11 网络架构(上)的内容中,我们已经探索过了 Ultralytics 框架的大体结构和实现原理。在本篇内容中,笔者将使用 JetBrains PyCharm 作为项目的 IDE,通过在 nn 子模块中进行修改来实现 CCAM 模块的导入,并以 cfg 子模块的 models/11/yolo11.yaml 为基础修改 YAML 配置来实现 CCAM 模块的引入,最终使用修改定制后的 ultralytics 实现新模型的训练、验证、测试以及 ONNX 格式的导出。本文中,笔者使用的操作系统为 Ubuntu 22.04.5 LTS,建议各位读者使用类 Unix 操作系统而非 Windows 以获得相似的阅读体验。
阅读指南
本系列博客分为上、下两个部分。其中,“(上)”篇将讲述 Ultralytics 框架的结构与基本实现原理;“(下)”篇则将讲述修改 YOLO 网络架构相关的关键模块,并以增添 CCAM 注意力模块为例给出一个修改定制的示例。
-
若您未接触过 Ultralytics 框架或是对配置训练/推理环境不够熟练,请先阅读 如何配置 Ultralytics YOLO11 的环境 并完成从源码安装 Ultralytics 框架。
-
若您已完成 Ultralytics 框架的环境配置与安装,但尚不清楚其内部实现或基本构造,请先阅读 定制你的 YOLO11 网络架构(上)。
-
若您对 Ultralytics 框架的项目结构已有一定的了解,且清楚其内部实现或基本原理,则可以直接阅读本文。
CCAM 模块概述
CCAM 是一种较为轻量级的注意力机制,它由 CAM(Channel Attention Module,通道注意力)与 CA(Coordinate Attention,联合注意力)融合而成:CAM 用于在通道上进行特征的提取与分析,通过对输入的特征图进行全局平均池化与全局最大池化,经由卷积计算出通道注意力权重后,使用 Sigmoid 激活函数进行处理,并将最终的通道注意力权重与原特征进行 Hadamard 乘积,应用注意力于重要特征通道上;而 CA 则在特征图的高度、宽度方向上进行池化运算,提取空间上的特征,并进行空间信息编码来增强全局特征信息,最终应用于输入特征图中。因此,CCAM 同时考虑通道与空间信息,使得模型可以专注于局部的细小特征的同时不丢失全局、长距离的特征信息。CCAM 的结构图如下所示。
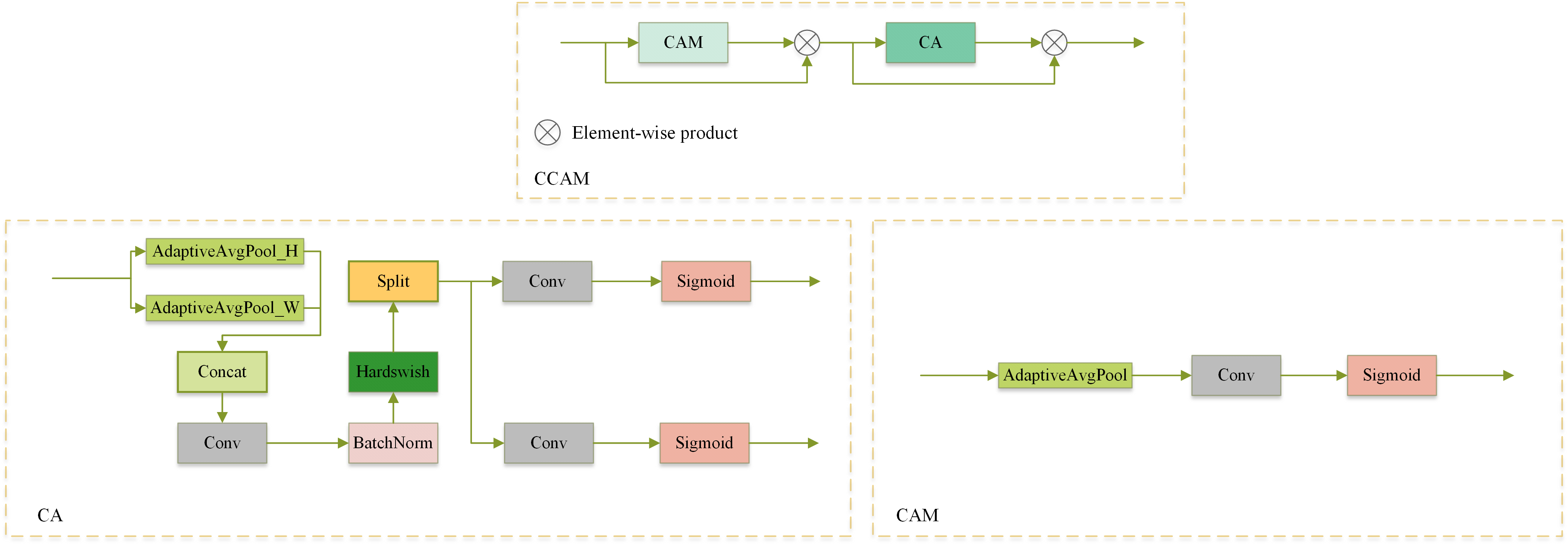
既然我们已经知道了 CCAM 由 CAM 和 CA 串联在一起,并且知道 CAM 和 CA 的模块结构,接下来我们就可以在 ultralytics 中分别加入这些模块,从而实现导入了。
在 Ultralytics 框架中导入要添加的模块
通过“(上)”篇的内容我们可以知道,ultralytics 中的 nn 子模块存放各类 PyTorch 模块,也提供面向各类训练/验证/推理任务的函数封装与接口。因此,nn 子模块将成为修改导入的重点,几乎一切修改都将围绕着 nn/modules 子模块及 nn/tasks.py 子模块进行。请注意,本节内容需要一定的 PyTorch 开发基础和工程能力,笔者将假定您已经基本熟悉 PyTorch 开发。
首先,在 PyCharm 中点开 ultralytics/nn/modules/block.py(以下将简称为 block.py),因为接下来将笔者把 CCAM 的定义存放在 block.py 中。由于 CCAM 由 CAM 和 CA 组成,因此我们还需要分别实现 CAM 和 CA 的定义。
但此时先不要急于实现 CAM 或 CA。我们可以在工程中搜索 ChannelAttention 或者 CoordinateAttention,看看这些模块是否已经被定义过了。很幸运,在 ultralytics/nn/modules/conv.py(以下将简称为 conv.py)中,我们能看到 ChannelAttention 已被定义,这意味着我们并不需要去手动实现 CAM,只需实现 CA,接着就能实现 CCAM。
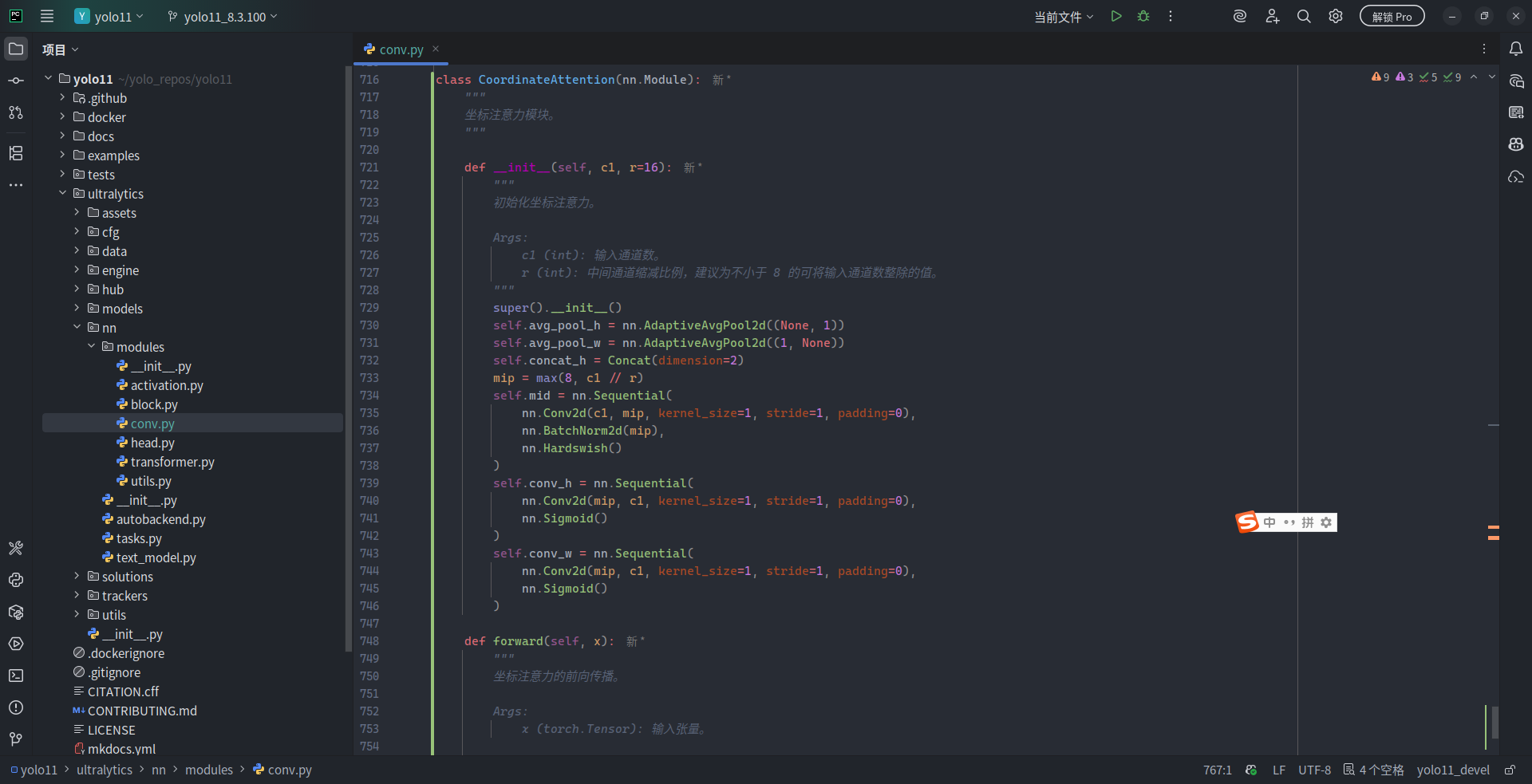
既然 Ultralytics 官方将 CAM 放在了 conv.py 中,我们也遵循 Ultralytics 的风格,将 CA 定义在 conv.py。在 conv.py 的末尾添加如下代码:
class CoordinateAttention(nn.Module):
"""
坐标注意力模块。
"""
def __init__(self, c1, r=16):
"""
初始化坐标注意力。
Args:
c1 (int): 输入通道数。
r (int): 中间通道缩减比例,建议为不小于 8 的可将输入通道数整除的值。
"""
super().__init__()
self.avg_pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.avg_pool_w = nn.AdaptiveAvgPool2d((1, None))
self.concat_h = Concat(dimension=2)
mip = max(8, c1 // r)
self.mid = nn.Sequential(
nn.Conv2d(c1, mip, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(mip),
nn.Hardswish()
)
self.conv_h = nn.Sequential(
nn.Conv2d(mip, c1, kernel_size=1, stride=1, padding=0),
nn.Sigmoid()
)
self.conv_w = nn.Sequential(
nn.Conv2d(mip, c1, kernel_size=1, stride=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
"""
坐标注意力的前向传播。
Args:
x (torch.Tensor): 输入张量。
Returns:
(torch.Tensor): 应用了坐标注意力的输出张量。
"""
n, c, h, w = x.size()
avg_pool_h_out = self.avg_pool_h(x) # 形状为 (n, c, h, 1)
avg_pool_w_out = self.avg_pool_w(x).permute(0, 1, 3, 2) # 变成 (n, c, w, 1)
y = self.mid(self.concat_h([avg_pool_h_out, avg_pool_w_out])) # 按高度维度拼接后变换为 (n, mid_c, h+w, 1)
avg_pool_h_out, avg_pool_w_out = torch.split(y, [h, w], dim=2) # 分割成 (n, mid_c, h, 1) 和 (n, mid_c, w, 1)
avg_pool_w_out = avg_pool_w_out.permute(0, 1, 3, 2) # 恢复到 (n, mid_c, 1, w)
attention_h = self.conv_h(avg_pool_h_out) # 生成注意力权重,形状为 (n, c, h, 1)
attention_w = self.conv_w(avg_pool_w_out) # 同理,(n, c, 1, w)
return x * attention_h * attention_w # 加权输出这段代码定义了 CoordinateAttention 模块。其中,构造函数中未显式声明 Split 模块,因为 PyTorch 中可以非常方便地使用 torch.split() 函数来实现分离操作,无需单独定义。当然,Concat 也可以使用 torch.cat() 来实现,但 conv.py 中已经有了 Concat 模块,因此可以直接拿来使用。
但是,光在 conv.py 中定义了 CoordinateAttention 还不够,毕竟 CCAM 模块将在 block.py 中实现,这意味着 block.py 中的代码会使用到 conv.py 中的内容。因此接下来,需要将 CoordinateAttention 在 __all__ 字段中注册。回到 conv.py 顶部,在 __all__ 的元组中加入 "CoordinateAttention":
__all__ = (
"Conv",
"Conv2",
"LightConv",
"DWConv",
"DWConvTranspose2d",
"ConvTranspose",
"Focus",
"GhostConv",
"ChannelAttention",
"SpatialAttention",
"CBAM",
"Concat",
"RepConv",
"Index",
"CoordinateAttention" # 新增项目,字符串请使用双引号
)
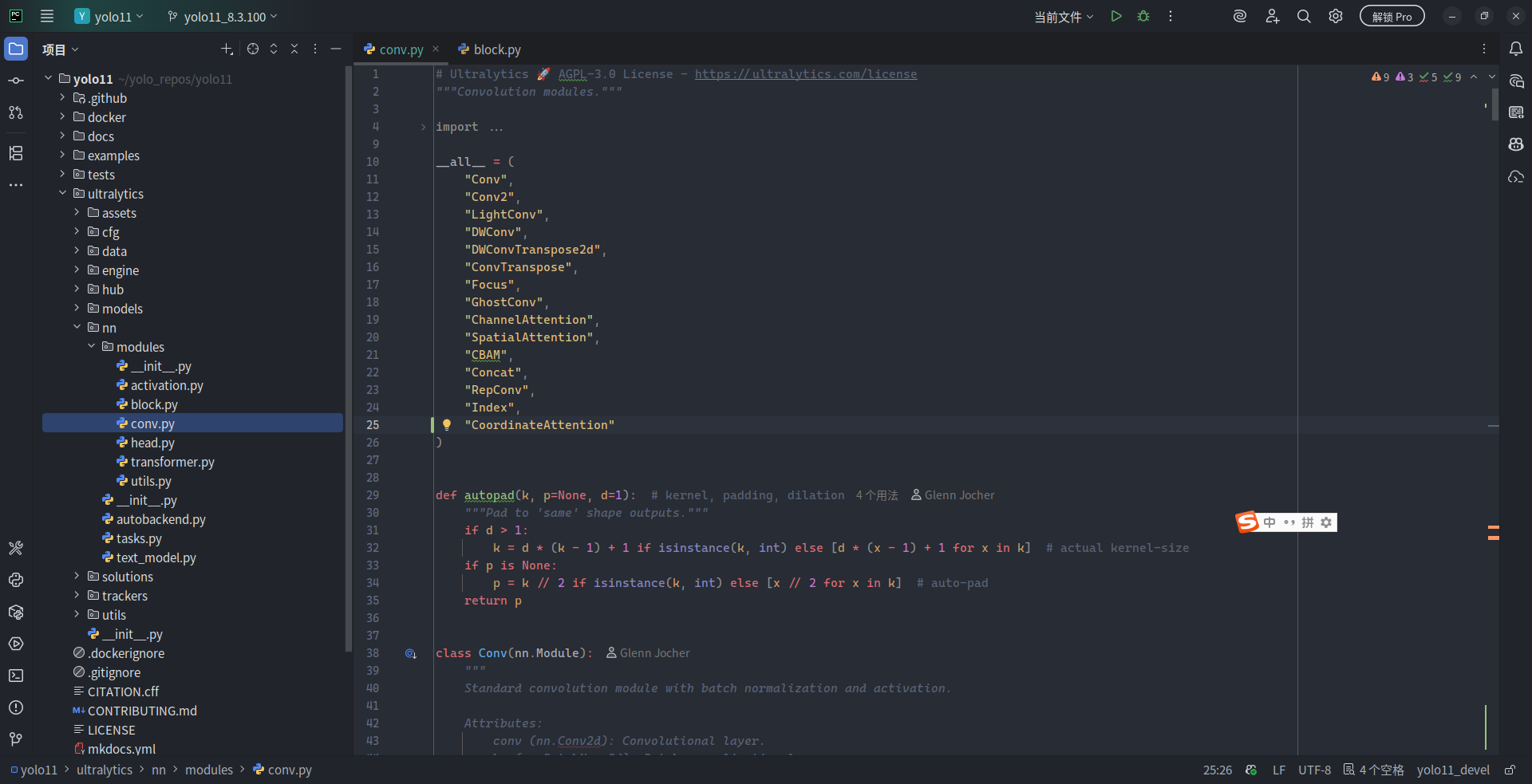
如此,CoordinateAttention 在 conv.py 中“注册”了自己的身份,这使得 block.py 以及上一级的 modules 子模块可以直接全局导入(如 import *)CoordinateAttention。至于为什么要使用 __all__ 来控制成员的导出与可见性,请参阅 PEP-8 - Style Guide for Python Code。同时,笔者此处未按照 Ultralytics 的代码风格,在最后一个元组成员后添加 ,,并将元组成员按首字母排序。若您需要为 Ultralytics 框架提交 PR 或是开放代码,请遵循 Ultralytics 代码规范与风格。
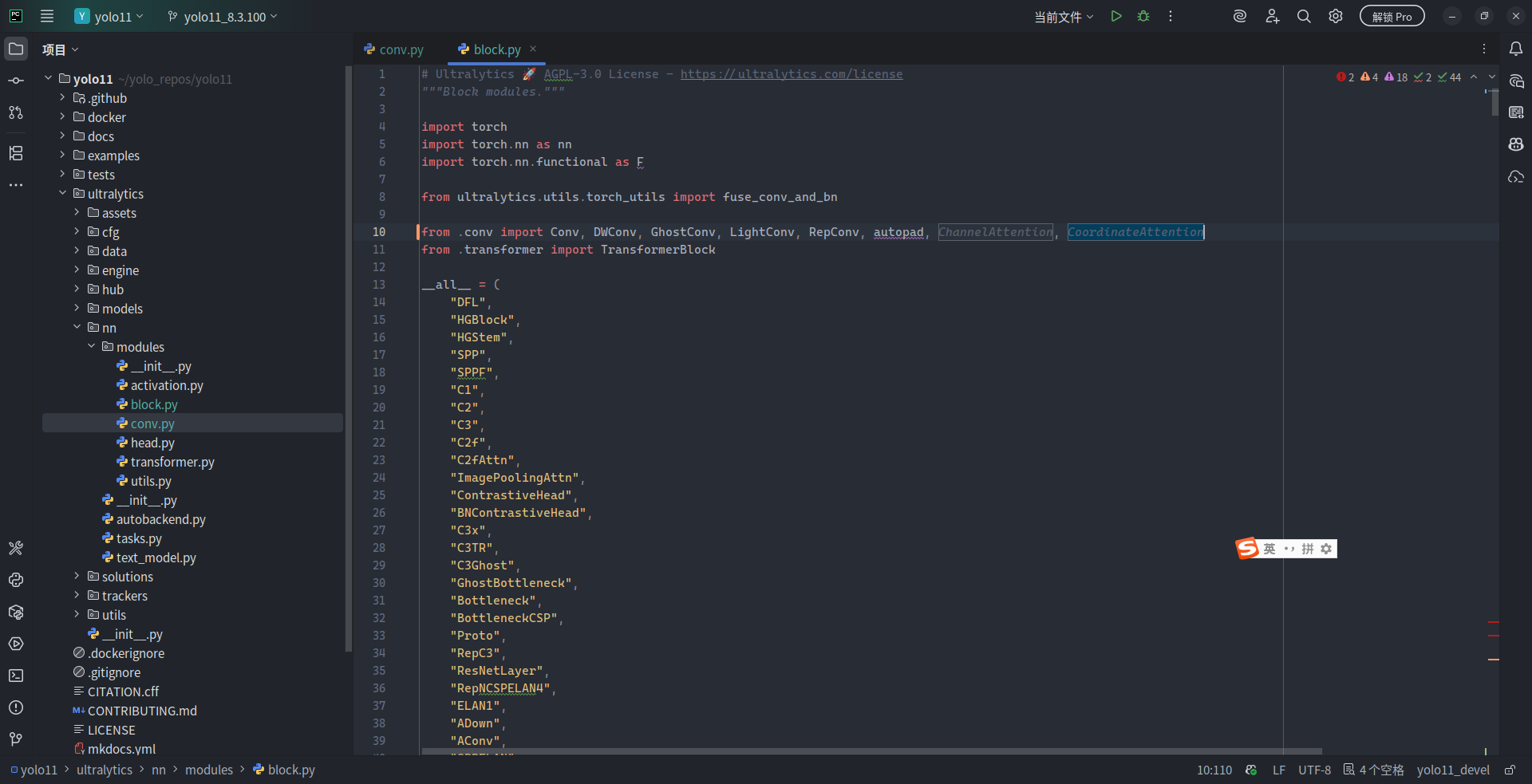
接下来,回到 block.py 中。在 block.py 开头的 from .conv import xxx 后面添加 ChannelAttention 和 CoordinateAttention 来导入 CAM 与 CA:
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.utils.torch_utils import fuse_conv_and_bn
from .conv import Conv, DWConv, GhostConv, LightConv, RepConv, autopad, ChannelAttention, CoordinateAttention # 新增导入 ChannelAttention 与 CoordinateAttention
from .transformer import TransformerBlock
在导入这两个模块后,我们就能在 block.py 中实现 CCAM 了。同样,在 block.py 的末尾,添加以下代码来定义 CCAM 模块:
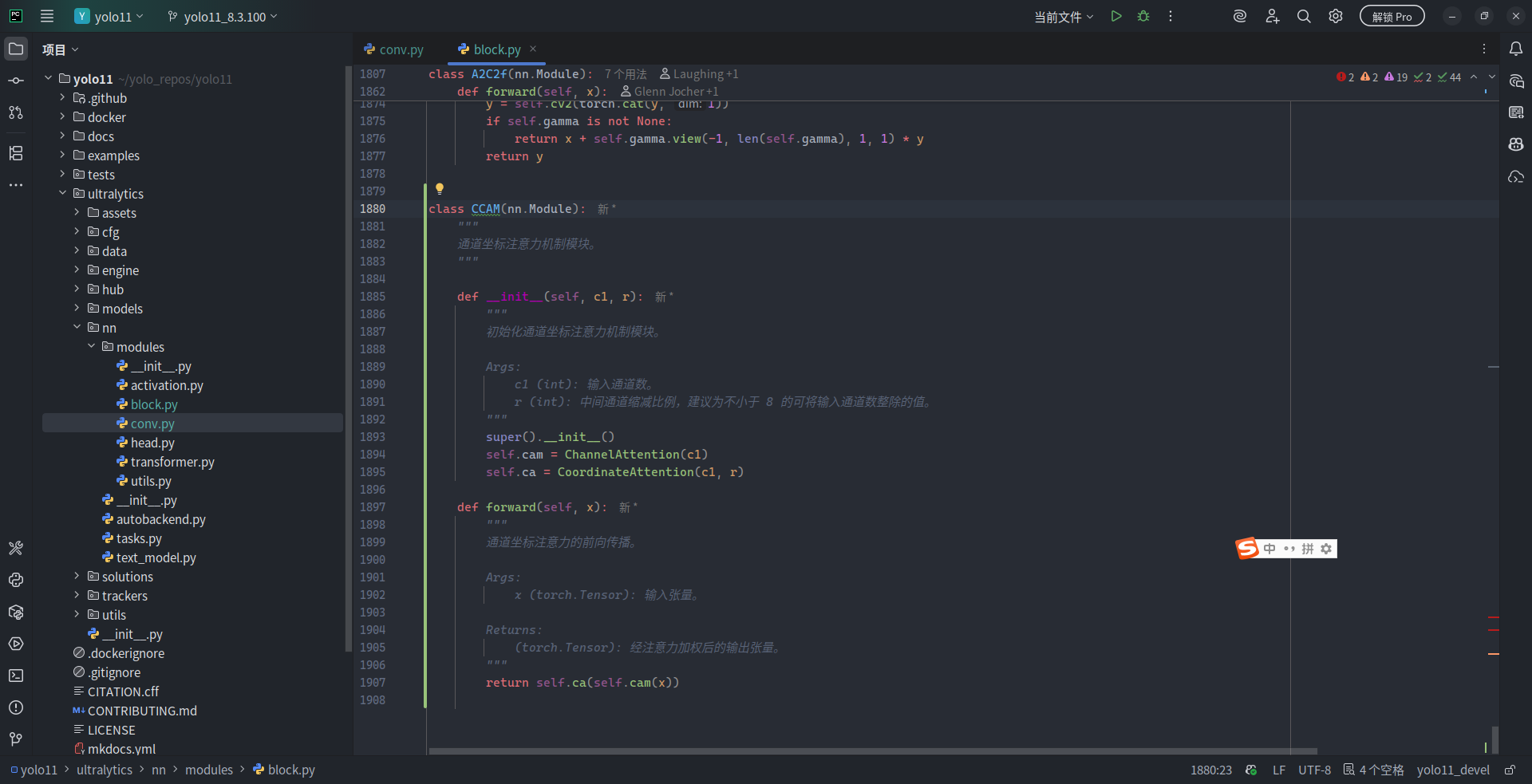
class CCAM(nn.Module):
"""
通道坐标注意力机制模块。
"""
def __init__(self, c1, r):
"""
初始化通道坐标注意力机制模块。
Args:
c1 (int): 输入通道数。
r (int): 中间通道缩减比例,建议为不小于 8 的可将输入通道数整除的值。
"""
super().__init__()
self.cam = ChannelAttention(c1)
self.ca = CoordinateAttention(c1, r)
def forward(self, x):
"""
通道坐标注意力的前向传播。
Args:
x (torch.Tensor): 输入张量。
Returns:
(torch.Tensor): 经注意力加权后的输出张量。
"""
return self.ca(self.cam(x))
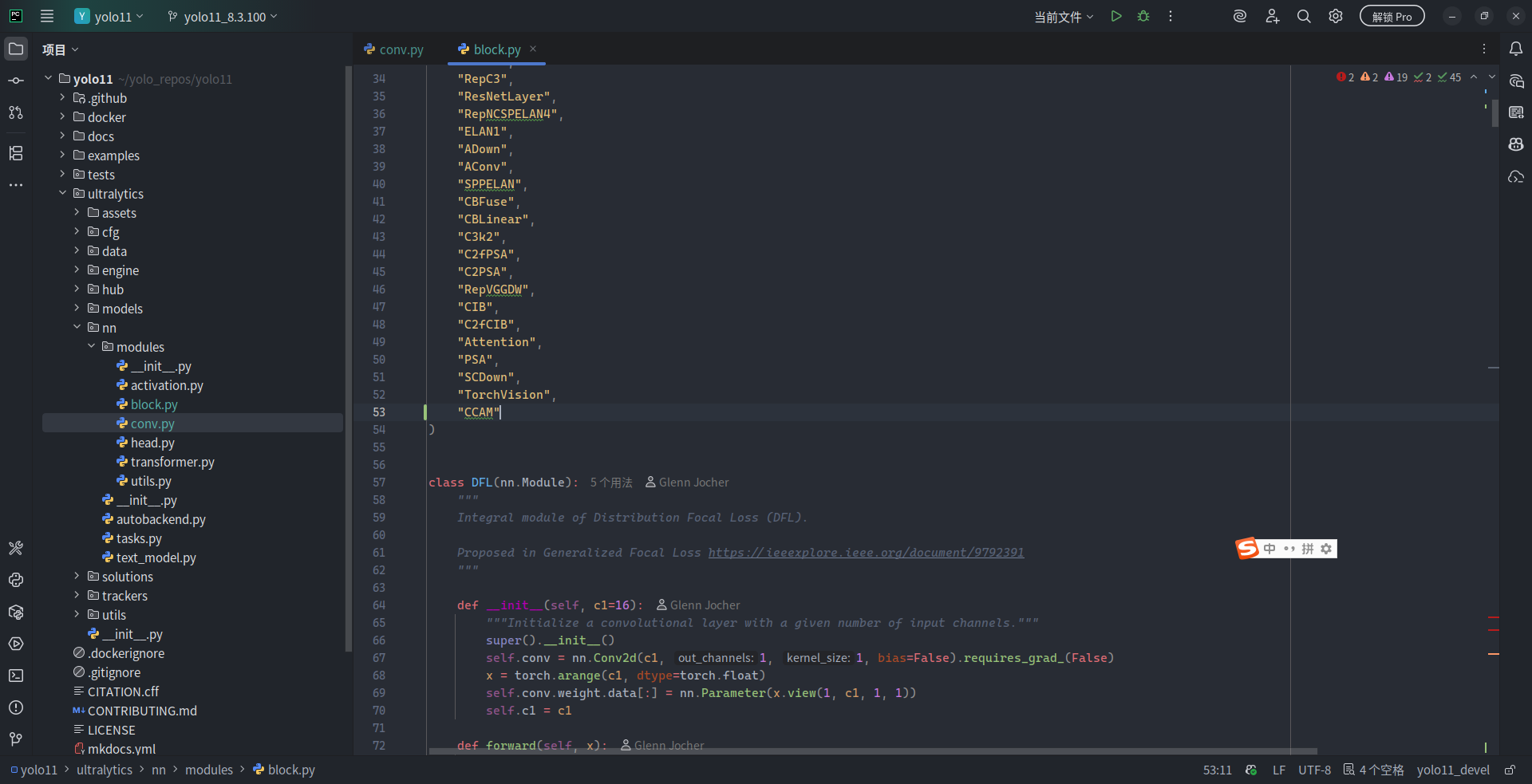
当然,也别忘了将 "CCAM" 注册到 block.py 的 __all__ 字段元组中:
__all__ = (
"DFL",
"HGBlock",
"HGStem",
"SPP",
"SPPF",
"C1",
"C2",
"C3",
"C2f",
"C2fAttn",
"ImagePoolingAttn",
"ContrastiveHead",
"BNContrastiveHead",
"C3x",
"C3TR",
"C3Ghost",
"GhostBottleneck",
"Bottleneck",
"BottleneckCSP",
"Proto",
"RepC3",
"ResNetLayer",
"RepNCSPELAN4",
"ELAN1",
"ADown",
"AConv",
"SPPELAN",
"CBFuse",
"CBLinear",
"C3k2",
"C2fPSA",
"C2PSA",
"RepVGGDW",
"CIB",
"C2fCIB",
"Attention",
"PSA",
"SCDown",
"TorchVision",
"CCAM" # 新增项目
)
然后,我们进入 ultralytics/nn/modules/__init__.py(以下简称为 __init__.py)中。相信了解 Python 工程开发的读者应该都知道 */__init__.py 会将当前目录声明成一个子模块,若您不清楚模块、子模块以及 */__init__.py 的作用,请参阅 Python Tutorial: Modules。在 __init__.py 的 from .block import xxx 导入部分,从 block.py 添加对 CCAM 的导入:
from .block import (
C1,
C2,
C2PSA,
C3,
C3TR,
CIB,
DFL,
ELAN1,
PSA,
SPP,
SPPELAN,
SPPF,
A2C2f,
AConv,
ADown,
Attention,
BNContrastiveHead,
Bottleneck,
BottleneckCSP,
C2f,
C2fAttn,
C2fCIB,
C2fPSA,
C3Ghost,
C3k2,
C3x,
CBFuse,
CBLinear,
ContrastiveHead,
GhostBottleneck,
HGBlock,
HGStem,
ImagePoolingAttn,
MaxSigmoidAttnBlock,
Proto,
RepC3,
RepNCSPELAN4,
RepVGGDW,
ResNetLayer,
SCDown,
TorchVision,
CCAM # 新增导入
)
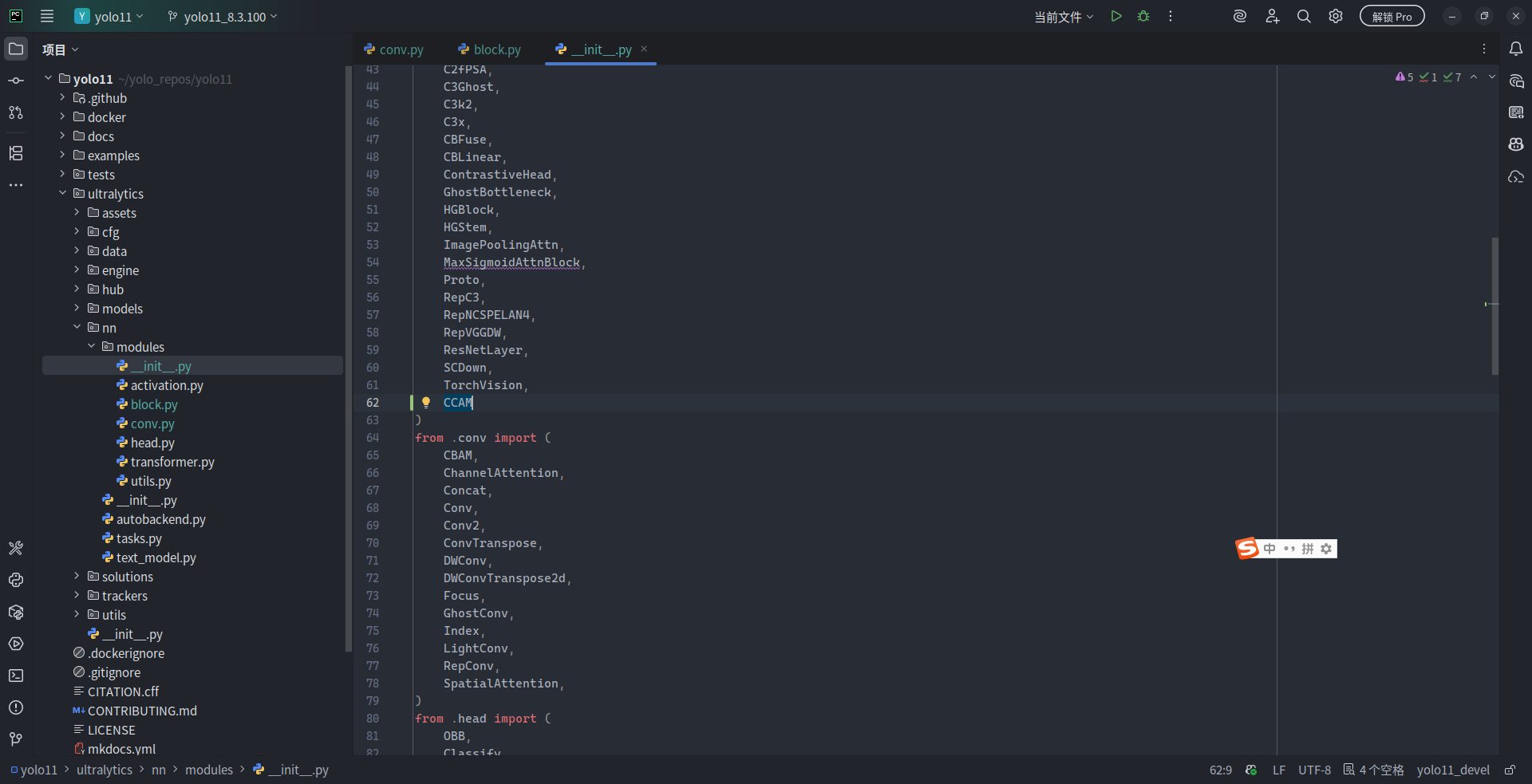
同时,在 __init__.py 的 __all__ 字段元组中增添 "CCAM":
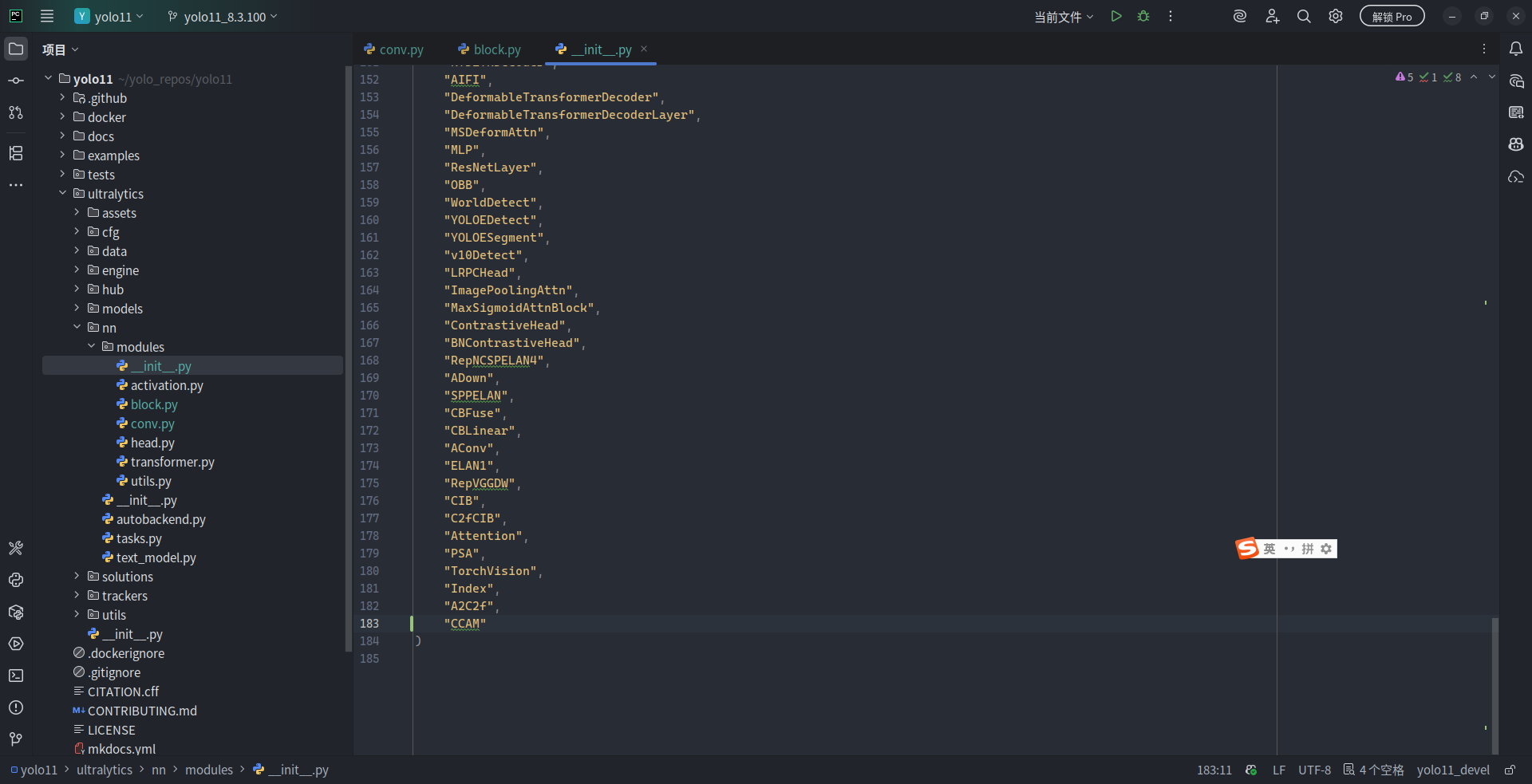
当然,如果您期望使用 CoordinateAttention 等其它模块的话,也可以像前文所述一样将 CoordinateAttention 等其它模块逐层导出,并按需导入。相信在尝试实践几次模块的导入、导出操作后,您将完全熟悉这个流程,并能迁移应用在其他 PyTorch 深度学习工程当中。
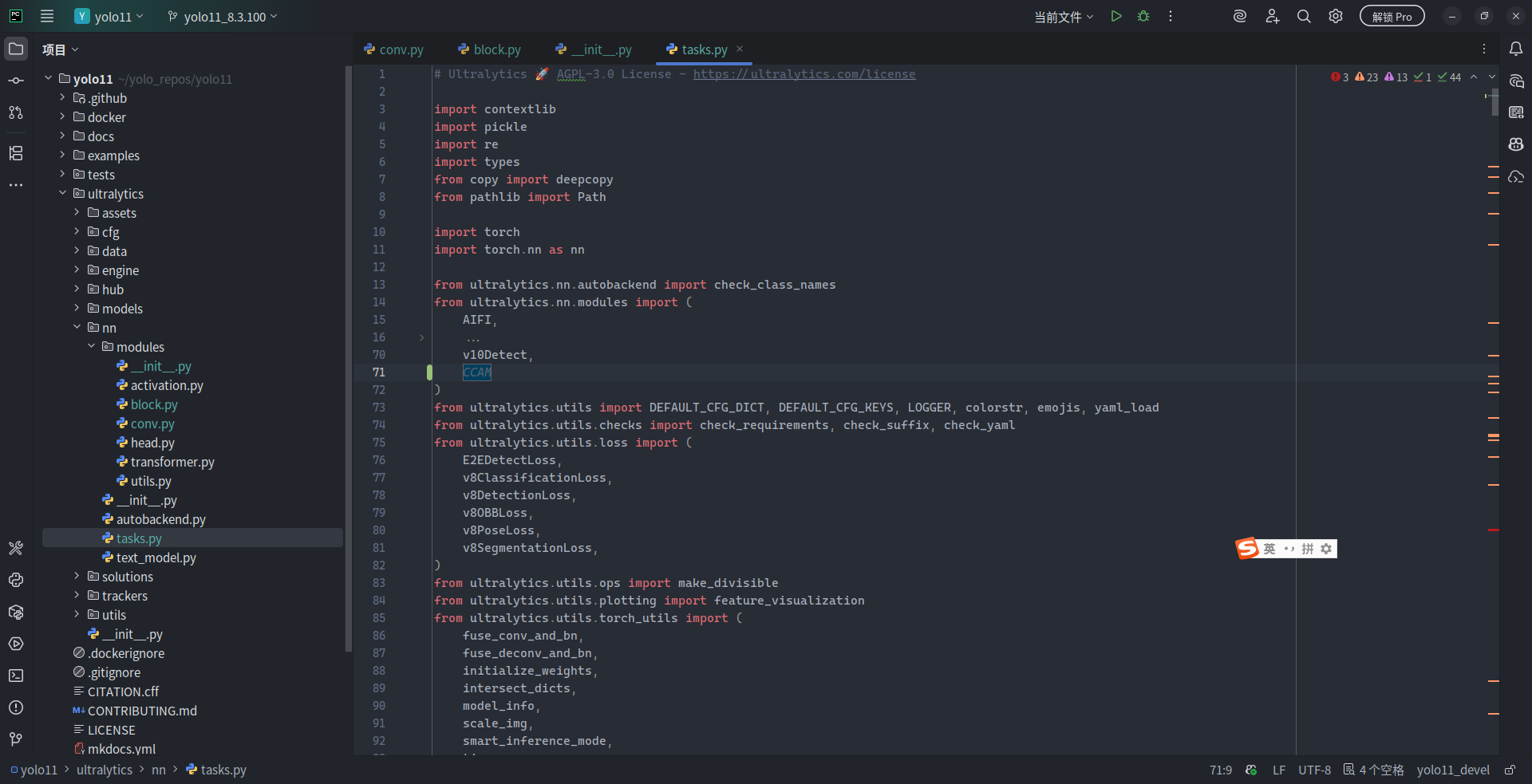
最后,在 ultralytics/nn/tasks.py(以下将简称为 tasks.py)中将 CCAM 导入,使得 ultralytics 能正确识别并应用到各类任务当中。在 tasks.py 的 from ultralytics.nn.modules import xxx 部分添加对 CCAM 的导入:
接着,在 tasks.py 中找到 parse_model() 函数,并在 parse_model() 函数体中找到 base_modules 变量,在其 frozenset 的花括号列表中添加 CCAM 项:
base_modules = frozenset(
{
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
C2fPSA,
C2PSA,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C3k2,
RepNCSPELAN4,
ELAN1,
ADown,
AConv,
SPPELAN,
C2fAttn,
C3,
C3TR,
C3Ghost,
torch.nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
PSA,
SCDown,
C2fCIB,
A2C2f,
CCAM # 新增项目
}
)
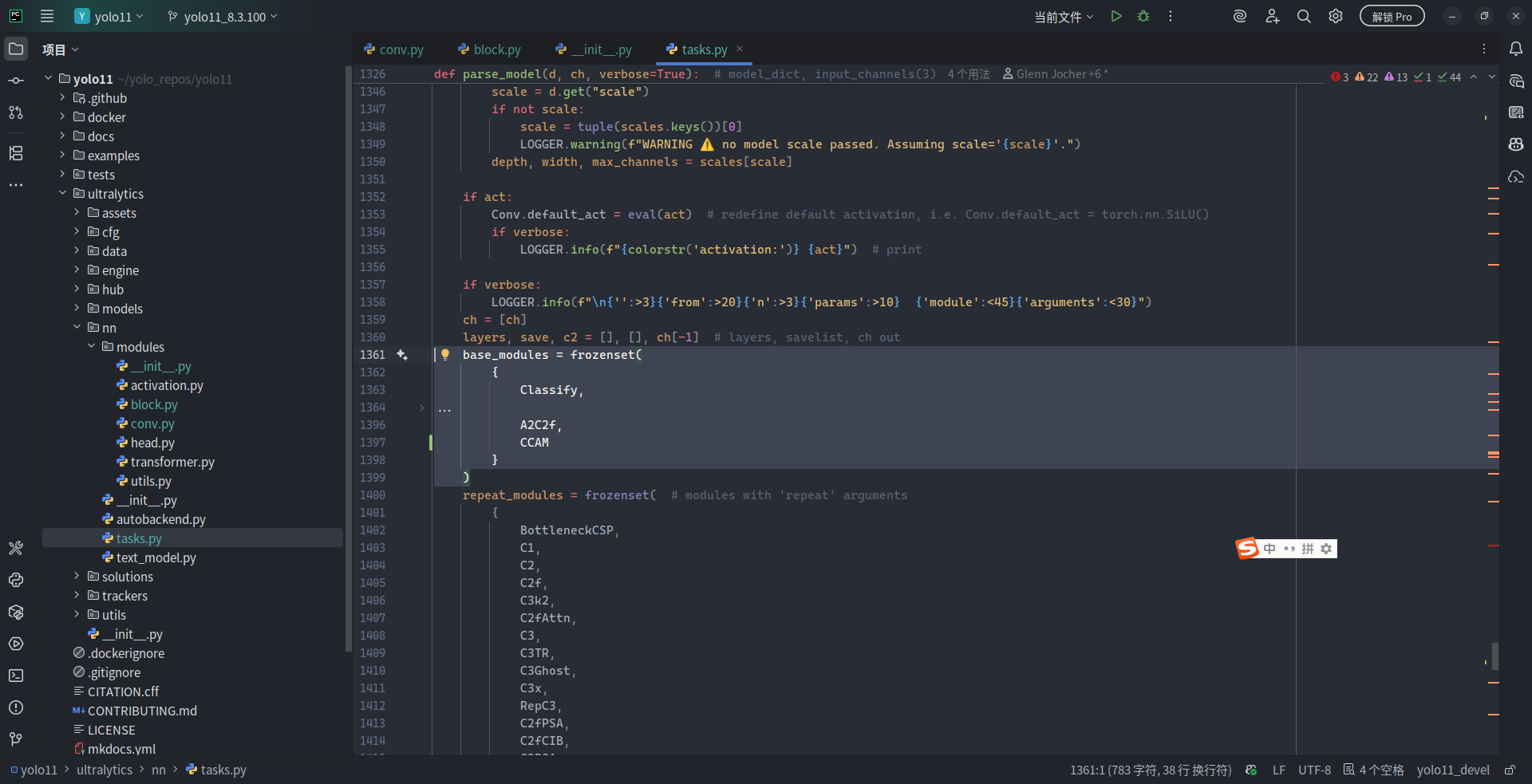
由于 CCAM 模块中不存在重复的结构(比如 C3k2 模块中的 Bottleneck),因此不需要再在下面的 repeat_modules 中加入 CCAM。至此,我们已经完成了将 CCAM 模块从实现到导入 Ultralytics 框架的全部过程。
在 YAML 配置中引入 CCAM 模块
虽然我们已经完成了 CCAM 模块在 Ultralytics 框架中的实现与导入,但要想在 YOLO11 模型中真正使用我们添加的新模块,还需要编辑 YAML 配置来指定 PyTorch 模型的装配方式。了解深度学习技术的读者看到 CCAM 这个名字及其构造后应该会不自觉地想到 CBAM 模块:CBAM(Convolutional Block Attention Module,卷积块注意力模块)是一种轻量级的即插即用注意力机制,它通过依次施加通道注意力和空间注意力,让卷积神经网络能够同时关注更重要的通道和空间位置,从而提升特征表示能力。而 CBAM 模块往往在 YOLO 架构中安插在 Neck 之后、Head 之前,因此我们将 CCAM 模块也安插在同样的位置:
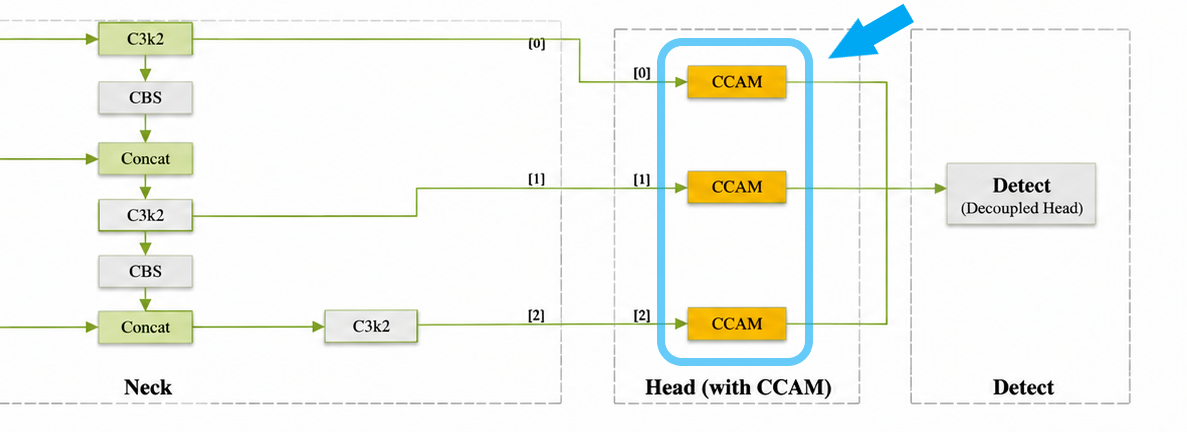
本文以目标检测的 YOLO11 模型为例,因此,对应具有 CCAM 模块改进的 YAML 配置将表示为如下(由 yolo11.yaml 派生):
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo11
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes, mainly used for COCO dataset
scales: # model compound scaling constants, i.e. 'model=yolo11n-ccam.yaml' will call yolo11-ccam.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
# YOLO11n-ccam backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n-ccam head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, CCAM, [256]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, CCAM, [512]] # 21 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, CCAM, [1024]] # 25 (P5/32-large)
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)若您需要对实例分割、OBB 或者是分类模型做配置修改,请分别基于 yolo11-seg.yaml、yolo11-obb.yaml 与 yolo11-cls.yaml 进行修改,它们的主干部分都大同小异,其它不同视觉任务且未提及的模型配置修改方法也是同理。
请注意,从 C3k2 到 CCAM 再到 Detect 头部的链路中,通道数应当保持不变,因此请注意 P3、P4、P5 对应的尺度情况。另外,Detect 头的输入从原来的 [16, 19, 22] 要变为 [17, 21, 25],因为模块的层级发生了变动,笔者已将新模型的层级标注在了 YAML 中。在本文示例中,笔者将该 YAML 文件保存为了 ultralytics/cfg/models/11/yolo11-ccam.yaml,保存到 cfg 子模块中的 YAML 配置文件将在安装 ultralytics 时被一同拷贝至 site-packages 或 dist-packages 目录内,这样在后续训练/验证的时候就不用指定该 YAML 文件的完整路径了。但不代表不能将该 YAML 配置保存到其它位置 —— 尤其是当您不想破坏 ultralytics/cfg 的原始文件结构或是提交 PR 时,将 YAML 配置放在工程目录外是更好的选择。至此,我们也完成了带有 CCAM 模块的 YOLO11 模型的配置修改。
新模型的训练、验证、测试及 ONNX 导出
训练、验证与测试
打开终端,切换到 ultralytics 仓库所在的目录,使用以下命令安装修改后的 Ultralytics 框架(若使用了虚拟环境,请注意激活正确的环境与解释器)。pip 包管理器会依据 pyproject.toml 中的指示自动配齐所需依赖。若所需依赖会覆盖掉您原本的一些配置,比如 NumPy 2.0.1 会导致 NumPy 1.26.4 被覆盖,从而导致如 ONNX Runtime 1.18.0 或者 OpenCV 4.9.0 不可用,则需要您在确保不出错的情况下,注释 pyproject.toml 中的一些内容或是后续手动修复依赖:
pip install .
当然,笔者前段时间在使用 YOLO26,因此 pip 包管理器会先卸载 ultralytics 8.4.x 再安装 8.3.100。若无报错,提示 Successfully installed ultralytics-8.3.100,则代表安装成功。
接着,在一个新的目录中,进行模型的训练测试。笔者选择了 ~/VSCodeProjects/train_models/yolo11-ccam,各位读者可自行选择。对于模型的训练、验证、测试和导出,既可以使用 CLI,也可以使用 Python 脚本。笔者过往的博客都使用了 CLI 命令,本文将使用 Python 脚本来完成同样的任务。使用以下命令来创建训练用的空 Python 脚本:
touch ./train_model.py笔者事先在 Roboflow 上下载了一个羽毛球的超小型目标检测数据集,总计有 182 幅图像,按 73:23:4 的比例划分为训练集、验证集和测试集。然后,在 train_model.py 中输入以下代码(记得看注释中的信息):
from ultralytics import YOLO
# 加载模型
model = YOLO('yolo11n-ccam.yaml') # 使用引入了 CCAM 的 YOLO11 目标检测模型配置(n 尺寸)
# 开始训练,训练结束后会自动验证
results = model.train(
data='./datasets/data.yaml', # 记得替换为真实的数据集 YAML 配置所在路径
epochs=100, # 使用 100 轮训练来进行轻量测试
imgsz=640, # 本文所用数据集为 640 × 640,若使用其它尺寸则需自行调整
batch=8, # 根据具体硬件配置调整 batch 的值,尽量使用 2 的幂次方
device=0, # 使用 GPU
workers=4, # 使用不大于 CPU 物理内核数的整数值
pretrained=False # 不使用预训练模型
)笔者此处使用了 Visual Studio Code 作为脚本的代码编辑器。请务必保证接下来运行该 Python 脚本的虚拟环境及 Python 解释器与刚才从源码安装 Ultralytics 的相同,否则会产生错误。接下来,运行该 Python 脚本,新模型将会开始训练,并且在训练结束后打印模型验证时具有的评价指标:
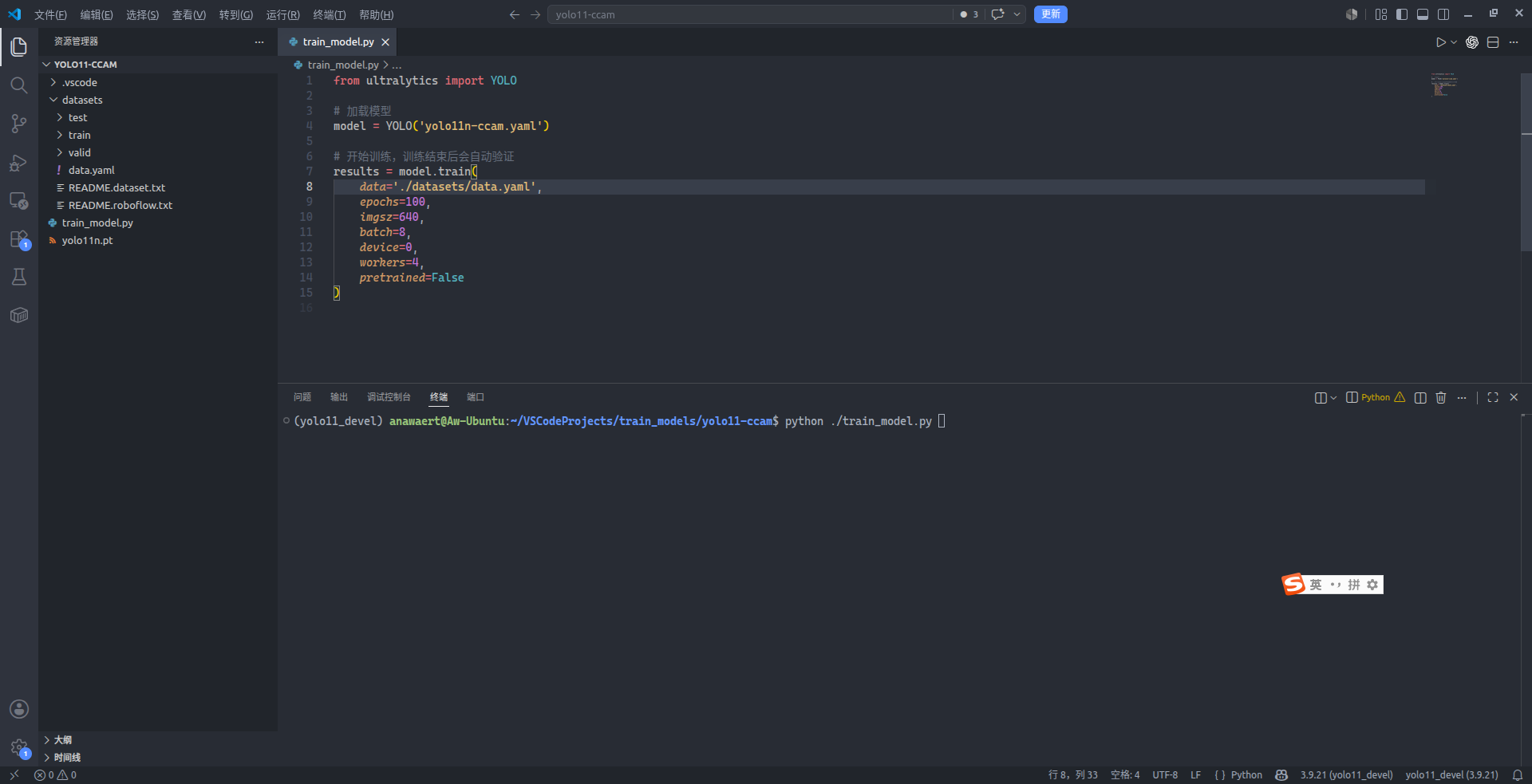
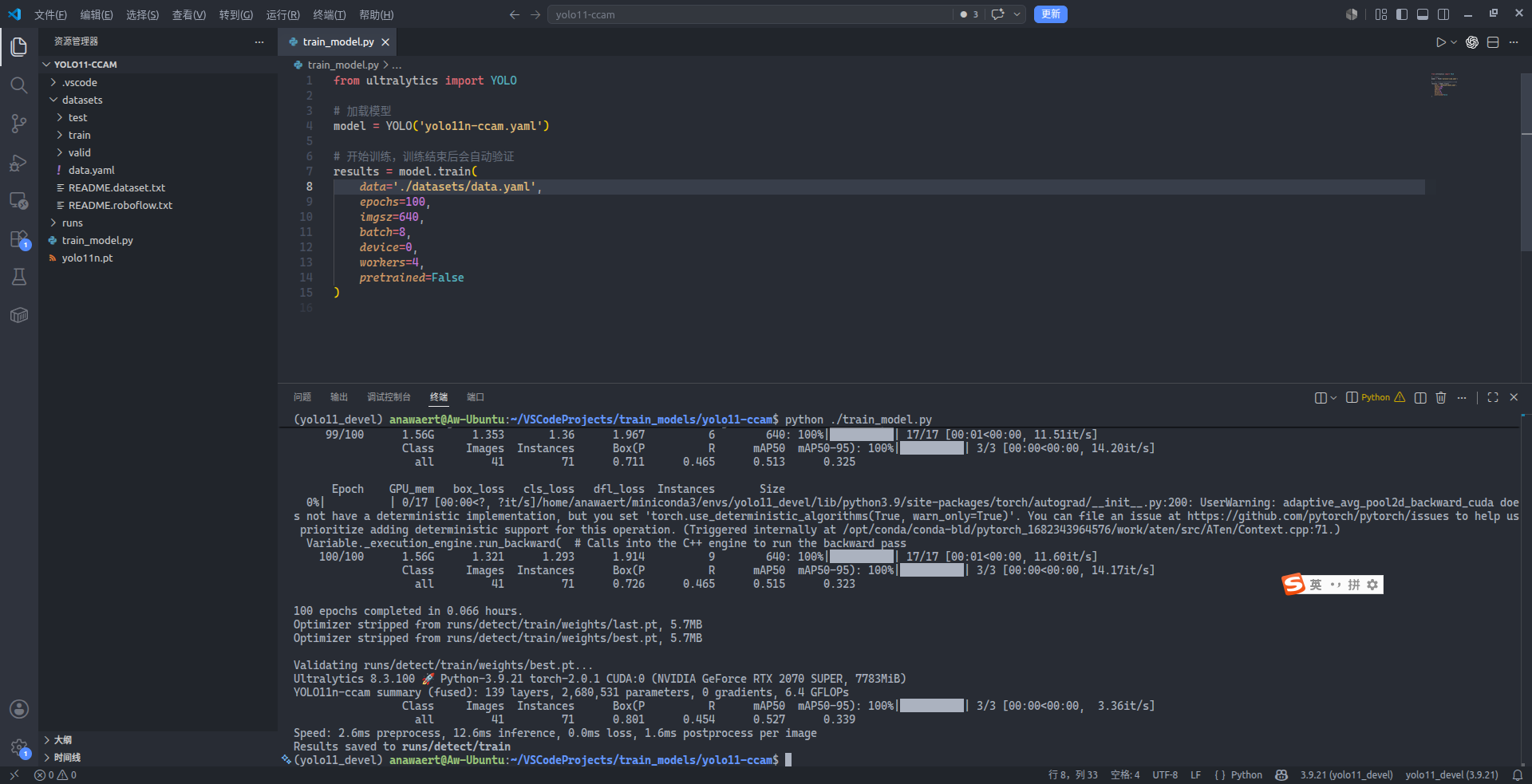
非常好,新模型在经过 100 轮的训练后,其 $P$、$R$、$mAP_{50}$ 与 $mAP_{50:95}$ 获得了最高分别为 80.1%、45.4%、52.7%、33.9% 的成绩。接下来,笔者从测试集中挑选了一张图片,使用训练获得的 ./runs/detect/train/weights/best.pt 来进行推理测试。在 train_model.py 中,将除了导入 YOLO 类型的其它代码注释掉后添加以下代码:
model = YOLO('./runs/detect/train/weights/best.pt') # Ultralytics 的默认训练权重存放路径
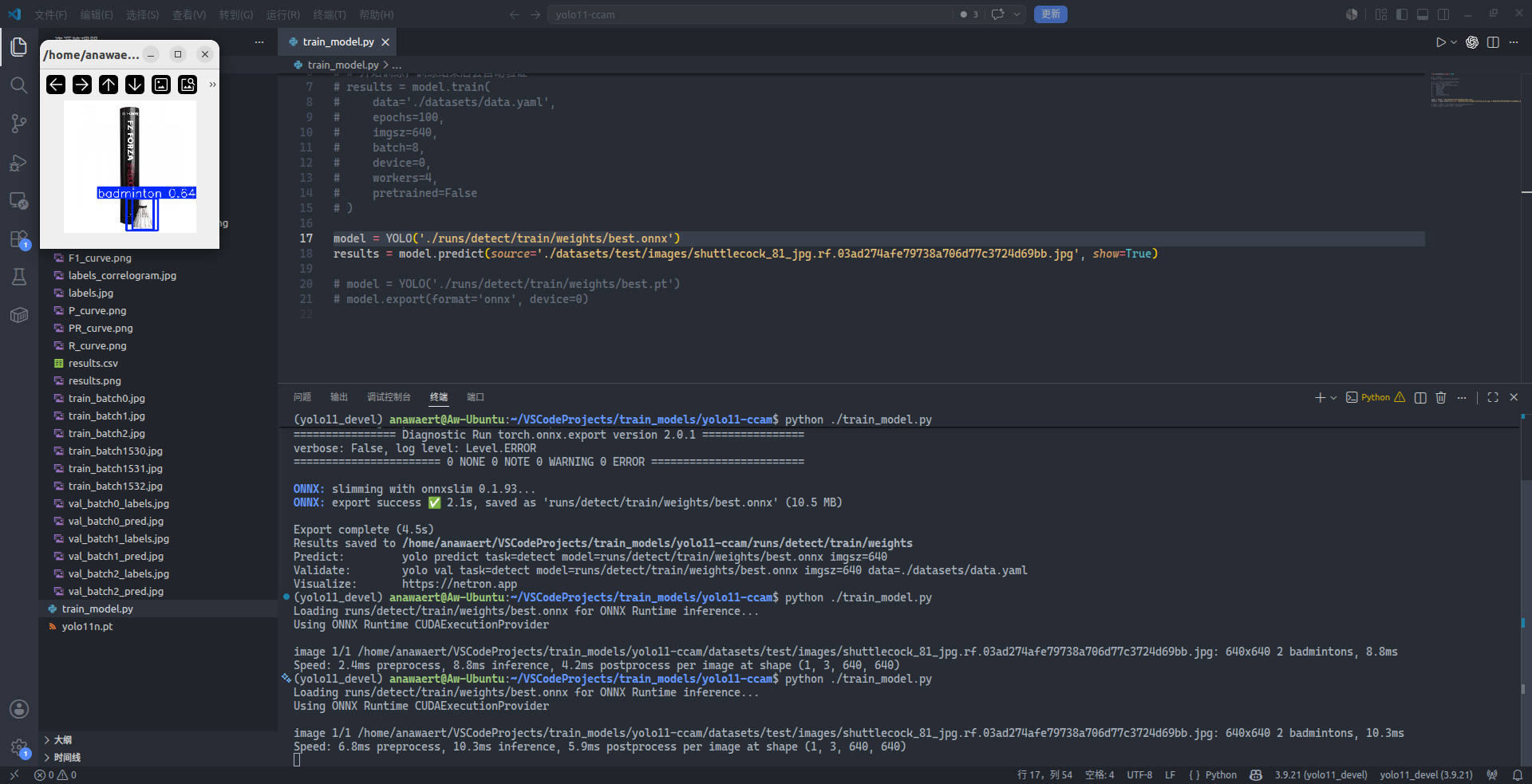
results = model.predict(source='./datasets/test/images/shuttlecock_81_jpg.rf.03ad274afe79738a706d77c3724d69bb.jpg', show=True) # source='<换成您要推理测试的图片的真实路径>'
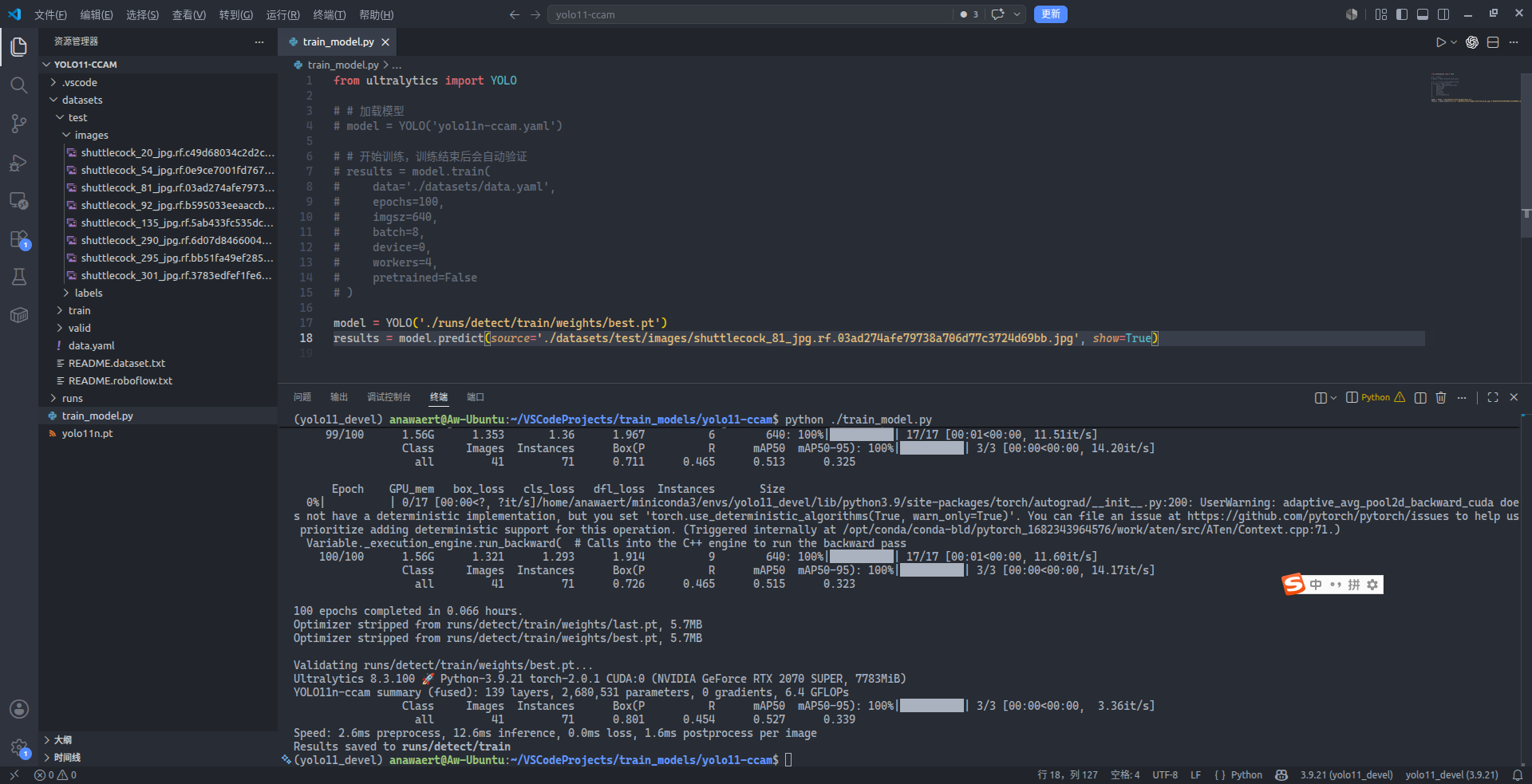
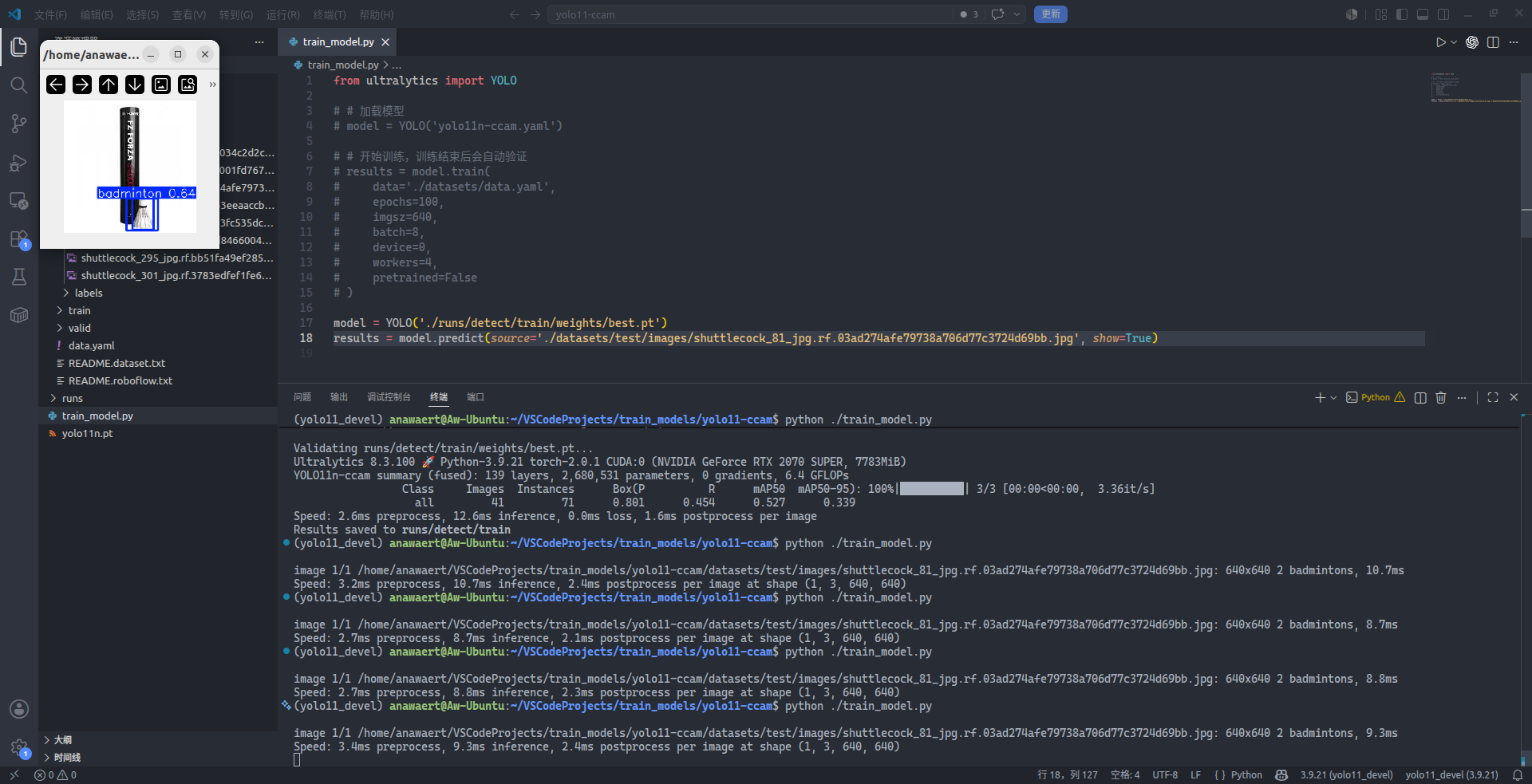
可以看到在左上角一闪而过的窗口中,出现了羽毛球目标的检测框以及相应的置信度,这表明模型已经可用。不过有些尴尬的是,一个羽毛球目标最终却获得了两个检测框,这显然不符合实际情况,那么接下来还需要对 $IoU$ 进行调整,使得 NMS 处理结果更符合实际。
ONNX 格式的导出与测试
类似地,将除了导入 YOLO 类型的其它代码注释掉后,添加以下代码来将 best.pt 导出为 ONNX 格式:
model = YOLO('./runs/detect/train/weights/best.pt')
model.export(format='onnx', device=0) # 使用 GPU 导出为 ONNX 格式
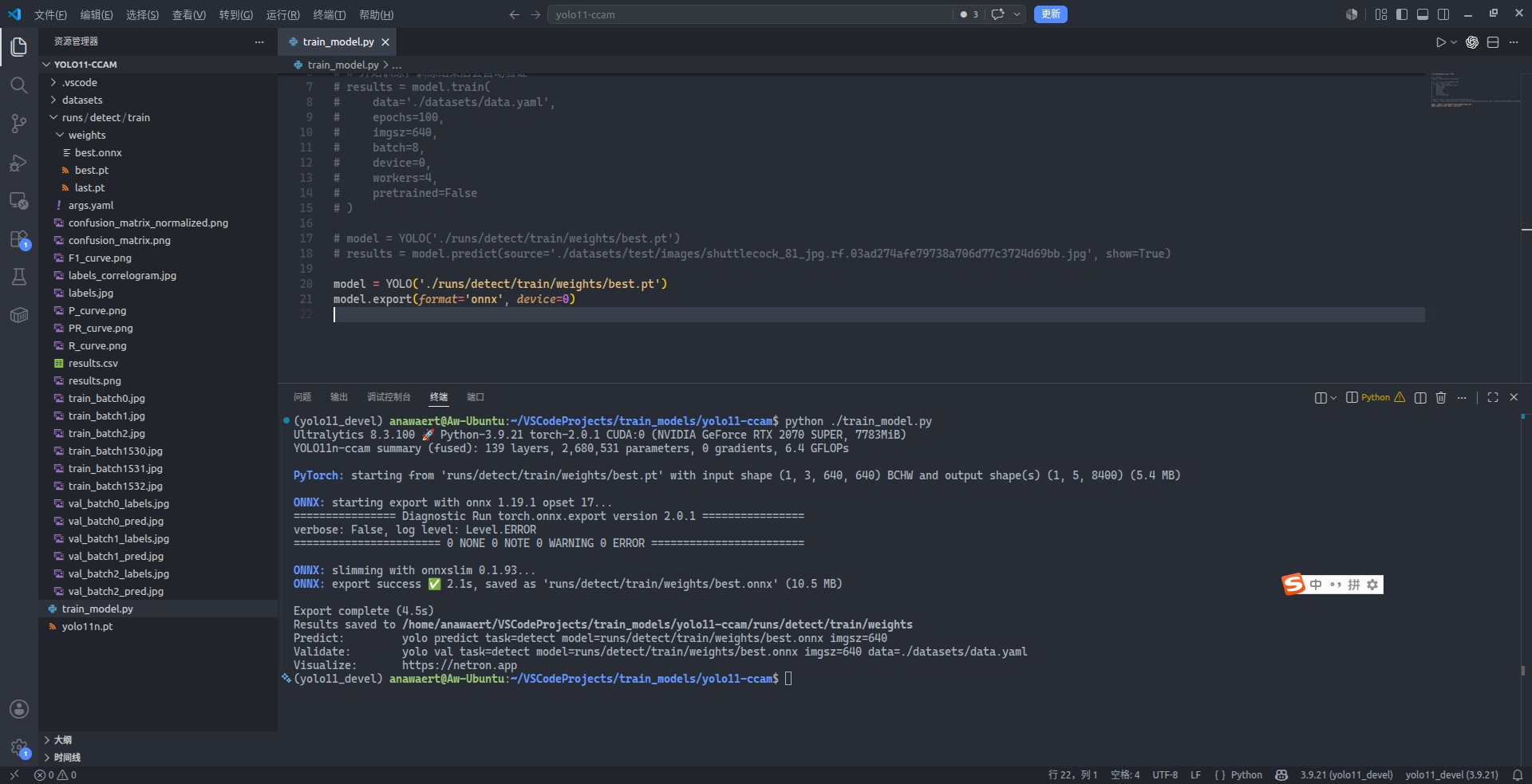
在 best.pt 旁边,能看到 best.onnx 已经生成,那么我们顺手来测试一下这个 ONNX 模型吧:注释掉当前用来导出的代码,接着取消先前测试代码的注释,并将 YOLO 构造函数中的路径填为 best.onnx 的路径:
model = YOLO('./runs/detect/train/weights/best.pt') # ONNX 模型的路径
results = model.predict(source='./datasets/test/images/shuttlecock_81_jpg.rf.03ad274afe79738a706d77c3724d69bb.jpg', show=True) # source='<换成您要推理测试的图片的真实路径>'
同样在左上角一闪而过的窗口中,可以看到与先前 best.pt 几乎相同的推理效果。至此,我们完成了对 Ultralytics YOLO 模型修改定制的所有流程。
Two more things
消除警告
细心的读者可能发现了,在训练时控制台输出了警告:UserWarning: adaptive_avg_pool2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation.
这表明在当前版本的 PyTorch 中使用自适应平均池化时,由于其在 CUDA 设备上的反向传播没有确定的实现,因此会导致训练结果不完全可复现。因此,PyTorch 发出警告,并告诉我们是在训练时设置了 torch.use_deterministic_algorithms(True, warn_only=True) 才导致没有抑制该警告,毕竟大多数人都期望使用确定性的算法嘛。当然,我们可以把警告关掉,这样就看不到了,但问题并没有真正地解决,反向传播时的结果不一致性仍然没有消除。那么可以怎么做呢?既然自适应平均池化在支持 CUDA 的 GPU 上结果不确定,那就让这一步在 CPU 上进行,不就能获得确定性的误差反向传播过程了吗 —— 毕竟 CPU 中的 ALU 获得计算结果的次序是确定的。因此,我们可以将内部使用了自适应平均池化的模块,也就是 CA 模块的实现进行如下改进:
class CoordinateAttention(nn.Module):
"""
坐标注意力模块。
"""
def __init__(self, c1, r=16):
"""
初始化坐标注意力。
Args:
c1 (int): 输入通道数。
r (int): 中间通道缩减比例,建议为不小于 8 的可将输入通道数整除的值。
"""
super().__init__()
self.avg_pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.avg_pool_w = nn.AdaptiveAvgPool2d((1, None))
self.concat_h = Concat(dimension=2)
mip = max(8, c1 // r)
self.mid = nn.Sequential(
nn.Conv2d(c1, mip, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(mip),
nn.Hardswish()
)
self.conv_h = nn.Sequential(
nn.Conv2d(mip, c1, kernel_size=1, stride=1, padding=0),
nn.Sigmoid()
)
self.conv_w = nn.Sequential(
nn.Conv2d(mip, c1, kernel_size=1, stride=1, padding=0),
nn.Sigmoid()
)
def forward(self, x):
"""
坐标注意力的前向传播。
Args:
x (torch.Tensor): 输入张量。
Returns:
(torch.Tensor): 应用了坐标注意力的输出张量。
"""
n, c, h, w = x.size()
# 改进:将张量拷贝一份到 CPU 后进行池化再将池化结果送回原设备。
avg_pool_h_out = self.avg_pool_h(x.cpu()).to(x.device) # 形状为 (n, c, h, 1)
avg_pool_w_out = self.avg_pool_w(x.cpu()).to(x.device).permute(0, 1, 3, 2) # 变成 (n, c, w, 1)
y = self.mid(self.concat_h([avg_pool_h_out, avg_pool_w_out])) # 按高度维度拼接后变换为 (n, mid_c, h+w, 1)
avg_pool_h_out, avg_pool_w_out = torch.split(y, [h, w], dim=2) # 分割成 (n, mid_c, h, 1) 和 (n, mid_c, w, 1)
avg_pool_w_out = avg_pool_w_out.permute(0, 1, 3, 2) # 恢复到 (n, mid_c, 1, w)
attention_h = self.conv_h(avg_pool_h_out) # 生成注意力权重,形状为 (n, c, h, 1)
attention_w = self.conv_w(avg_pool_w_out) # 同理,(n, c, 1, w)
return x * attention_h * attention_w # 加权输出再重新过一遍上面的安装、训练流程。由于主流的消费级 x86/amd64 CPU 往往不直接支持半精度浮点运算,因此需要将 AMP(自动混合精度)关闭,也就是在 model.train() 中设置 amp=False:
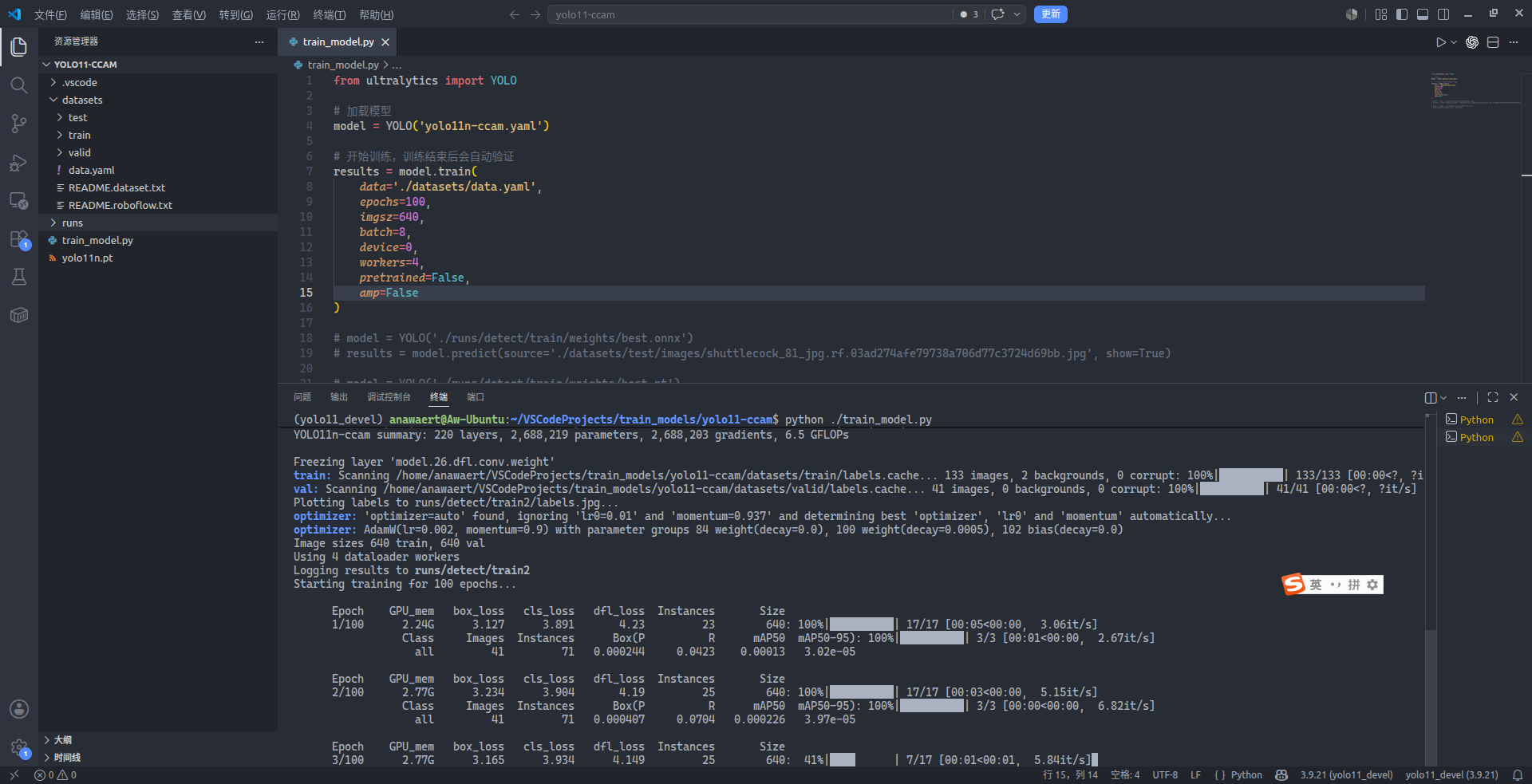
运行训练脚本,可以发现警告的确消失了,但显然 CPU 的并行计算能力不如 GPU,因此训练时间也被大幅度提高了:
消融对比实验
在统一使用了如上图所示训练参数(使用改进实现后的 CCAM,轮数 100,批次 8,DataLoader 并发数 4,不使用预训练模型与 AMP)的条件下,引入了 CCAM 和原始的 YOLO11(n 尺寸)模型的消融对比实验结果如下(T 代表“是”,F 代表“否”,下同):
| 是否引入 CCAM | $P$ | $R$ | $mAP_{50}$ | $mAP_{50:95}$ |
|---|---|---|---|---|
| T | 73.0% | 49.3% | 52.3% | 31.6% |
| F | 83.5% | 47.9% | 57.7% | 35.2% |
有些尴尬,引入了 CCAM 的 YOLO11 模型的表现还不如原始模型,尤其是精度 $P$,居然能被甩开 10.5%!虽然召回率 $R$ 比原始模型高了 1.4%,但如此低的 $mAP_{50}$ 与 $mAP_{50:95}$ 仍宣告了该模型的失败。
但是,还需思考一个问题:CCAM 为网络引入了更多的参数和梯度,并且其注意力机制中用到了平均池化,某些突出的特征被“抹平”了,这意味着引入了 CCAM 的 YOLO11 应当需要更多的训练轮数来实现收敛。因此,笔者将训练轮数调至 200 轮,并设置 150 轮起无进步自动停练,其余训练参数保持不变,再次进行引入了 CCAM 和原始的 YOLO11(n 尺寸)模型的消融对比实验:
同时,本次实验的结果如下:
| 是否引入 CCAM | $P$ | $R$ | $mAP_{50}$ | $mAP_{50:95}$ |
|---|---|---|---|---|
| T | 82.9% | 59.2% | 63.2% | 41.4% |
| F | 83.5% | 57.0% | 61.1% | 40.9% |
实验结果表明,(引入了 CCAM 的)YOLO11 的确需要更多的训练轮数来实现收敛,但在相同训练参数(使用改进实现后的 CCAM,轮数 200,150 轮起自动停练,批次 8,DataLoader 并发数 4,不使用预训练模型与 AMP)的条件下,引入了 CCAM 的 YOLO11(n 尺寸)模型相比原始模型的 $R$、$mAP_{50}$、$mAP_{50:95}$ 分别提高了 2.2%、2.1% 与 0.5%,虽然 $P$ 略有下降,但还是获得了综合性的提升。CCAM 与 CBAM 很像,都像是拿一点精度换更高的召回和 $AP$。
总结
本文详细讲述了如何在 Ultralytics 框架中完整集成和使用自定义神经网络模块(以 CCAM 注意力机制为例)。首先介绍了 CCAM 的原理,然后阐述了在 nn 子模块的 conv.py 和 block.py 中实现这些模块的具体步骤,包括代码编写、在 __all__ 中注册、逐级导入到 tasks.py 等工程实践。接着详解了如何修改 YAML 配置文件(基于 yolo11.yaml),在 Neck 之后、Head 之前插入 CCAM 模块。同时,本文还进一步展示了使用修改后框架进行模型训练、验证、测试和 ONNX 格式导出的完整流程,解决了自适应平均池化导致的训练不确定性问题,最后通过两轮消融对比实验验证了 CCAM 模块在更充分训练(200 轮)下能显著提升模型的召回率和 $mAP$ 指标,整体性能提升明显。若各位有更多关于 Ultralytics YOLO 定制修改的想法,欢迎在下方评论区留言讨论。本系列教程博客也到此结束,未来,笔者在定制 YOLO 模型方面将以简化的方式继续分享算法改进相关的内容。
附件
点击以下载本文中所用的羽毛球数据集(笔者已删除与 Roboflow 相关的冗余信息)。