定制你的 YOLO11 网络架构(上)
前言
在步入 2026 年之际,知名计算机视觉目标检测框架研发机构 Ultralytics 已然将其同名框架升级到了 8.4 版本,即对应着 YOLO26 的正式发布与投入实用。而在过去的大半年时间里,由于笔者的个人事务繁忙,未能持续研究 Ultralytics YOLO 系列深度学习框架。恰逢近期笔者相对时间宽裕,也有朋友也想了解一些有关 Ultralytics YOLO 系列框架的结构与定制,且笔者恰有 Ultralytics 8.3 (YOLO11) 的网络架构改进经验,因此决定编写一个 YOLO 网络修改定制博客。受限于笔者的水平,本系列博客将主要从工程的角度出发,较为粗略地讲述 Ultralytics 框架的结构、基本实现原理、关键模块以及修改定制示例。
阅读指南
本系列博客分为上、下两个部分。其中,“(上)”篇将讲述 Ultralytics 框架的结构与基本实现原理;“(下)”篇则将讲述修改 YOLO 网络架构相关的关键模块,并以增添 CCAM 注意力模块为例给出一个修改定制的示例。
-
若您未接触过 Ultralytics 框架或是对配置训练/推理环境不够熟练,请先阅读 如何配置 Ultralytics YOLO11 的环境 并完成从源码安装 Ultralytics 框架。
-
若您已完成 Ultralytics 框架的环境配置与安装,则可以直接阅读本文,但需要注意本文默认的 Ultralytics 安装配置方式与 如何配置 Ultralytics YOLO11 的环境 一致。若您是直接从 pip/uv 等包管理器或是使用 conda 环境直接安装的 Ultralytics,请卸载并改为从源码安装的方式。
-
若您对 Ultralytics 框架的项目结构有一定的了解,且清楚其内部实现或基本原理,则可以跳过本篇内容,直接阅读 定制你的 YOLO11 网络架构(下)。当然,快速阅读本篇内容后再读后文也是一个不错的选择 —— 顺便回顾一下。
探索 Ultralytics
由于从源代码安装 ultralytics 时,克隆到本地的仓库本质上也是一个 Python 项目,因此可以使用主流的 IDE 或代码编辑器打开这个仓库目录,比如 Visual Studio Code 或 PyCharm,笔者选择了 PyCharm 作为本文演示所用的 IDE。但又由于 Ultralytics 官方已在 2026 年初发布了 ultralytics 8.4,即 YOLO26,故在打开仓库进行探索前还需要将仓库“回退”至 8.3.x。笔者此处选择了 2025 年中期的 utralytics 8.3.100 版本,因此在 yolo11 目录下执行如下操作:
git checkout -b yolo11_8.3.100 v8.3.100
这个命令从 8.3.100 节点处分出一条新的本地分支 “yolo11_8.3.100”,仓库在这个新分支下相当于回退到了 8.3.100 时的状态。当然,如果您的 ultralytics 版本就是 8.3.x 系列,则回退操作不是必须得,但为了阅读与体验的一致性,笔者仍然建议回退至文中的相同版本。
然后,使用 PyCharm 打开 yolo11 目录:
在 PyCharm 左边栏的资源管理器中,各个目录及文件的功能如下所示。其中,ultralytics 模块是我们接下来要探索的重点:
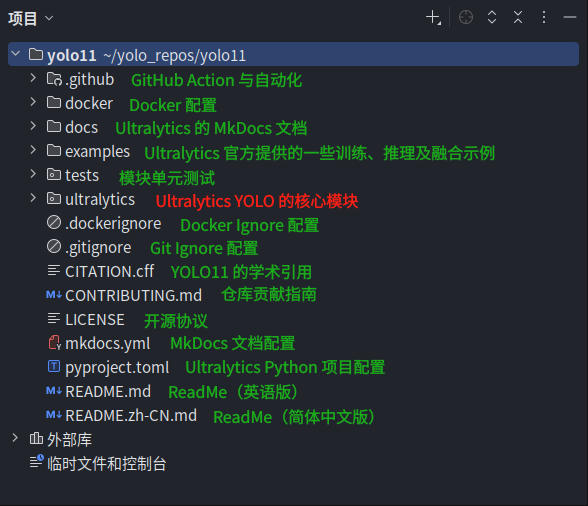

模型的序列化与超参数配置
我们先来看看 cfg 子模块是如何定义序列化后的模型以及超参数的配置的。展开 cfg 目录树,不难发现 cfg 下还分为了 datasets、models、solutions 和 trackers 子目录,以及一个 __init__.py 和 default.yaml 文件。
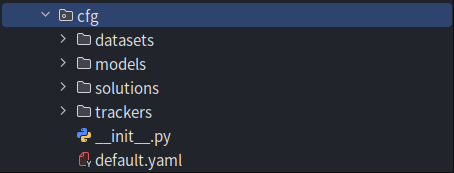
依据目录名称,不难猜出这几个目录应该分别与数据集、(YOLO) 模型、“解决方案”和追踪器有关。再点开 default.yaml,就会看到一系列键值对:如第 12 行中的 epochs: 100,这是定义了默认的训练轮数为 100。显然,default.yaml 中的键值对实际上是 Ultralytics 框架执行特定功能(模型训练/验证/推理与数据展示)时使用的一些默认超参数,通过修改 default.yaml 中的内容,即可改变默认训练设定:比如修改第 26 行处 optimizer: auto 为 optimizer: SGD 后,即可在模型训练时使用 SGD 随机梯度下降优化器。
接着,展开 cfg/models 目录,立马发现有多个形如版本号的子目录。联想到往期的 YOLO 版本,如 YOLOv5、YOLOv8 等,不难想到这些目录存放的就是各版本 YOLO 模型的配置了。
再展开 cfg/models/11,里面果然有许多 .yaml 文件。打开 yolo11.yaml,文本编辑器即向我们展示了该配置文件中的具体内容:
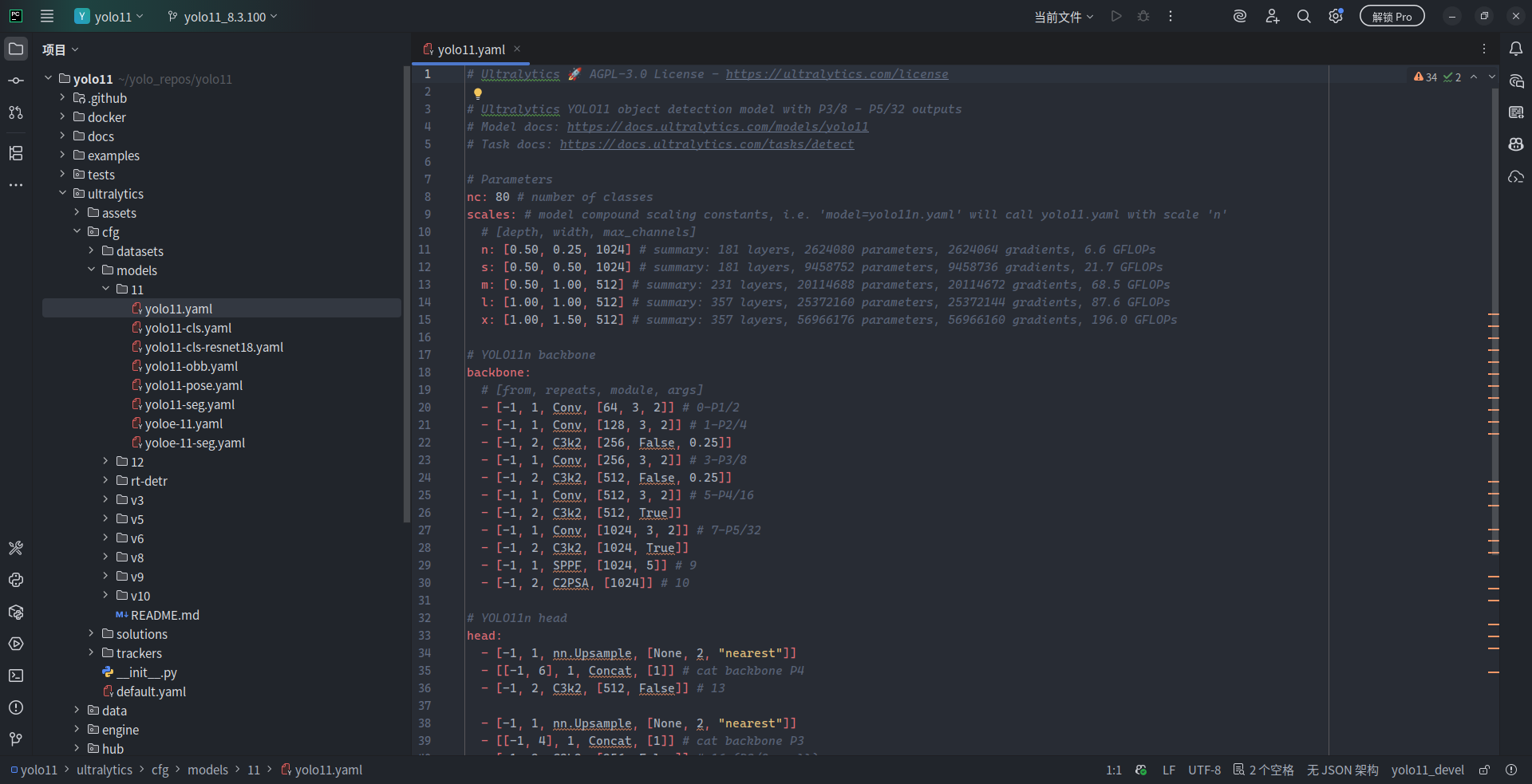
了解 Ultralytics YOLO 系列模型的读者都知道,Ultralytics 喜欢为模型划分多种尺寸来满足不同设备上的部署需求,从大到小为 x (x-large)、l (large)、m (medium)、s (small) 和 n (nano)。上图中第 11 - 15 行即定义了不同的网络层数、宽度和最大通道数来约束模型的尺寸,从而实现多尺寸的模型划分。
而从第 18 行开始,正式进入模型网络架构的关键定义部分。笔者先放一张取自 LearnOpenCV 的 YOLO11 网络结构图与 yolo11.yaml 中第 18 - 50 行的结构定义的对照图,请各位读者先仔细阅读比对:
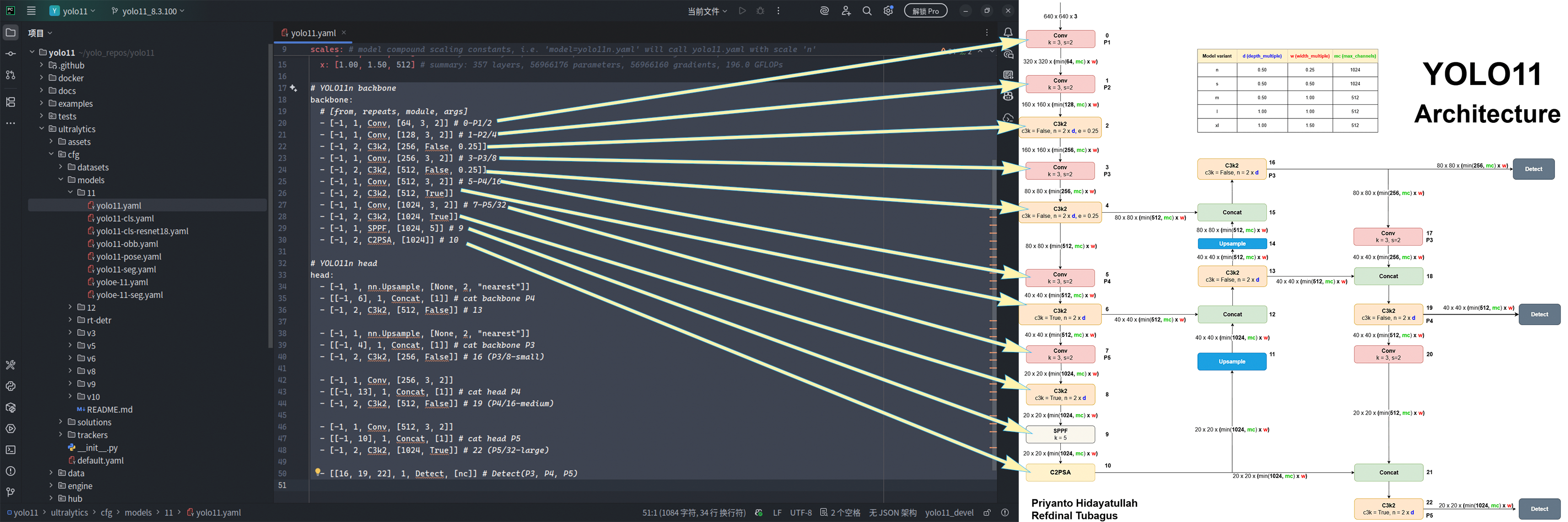
细心的读者应该发现了,yolo11.yaml 中 backbone 部分中,形如 [from, repeats, module, args] 的列表的 module 名称似乎能和网络架构图中基本一一对应,甚至顺序都基本对应。没错,这就是 ultralytics 的一项朴素而伟大的实现:将 (PyTorch) 深度学习模型由传统的 “class MyNet(nn.Module)” 形式转为了使用 YAML 键值对文本的序列化形式。也就是说,在 ultralytics 中修改模型结构的定义时,若 Ultralytics 框架中已经集成了某些模块的 PyTorch 模块定义,那么我们就可以直接将其写进这个 YAML 文件,而无需自己手动在 PyTorch 上下文的代码中修改模型的定义(比如在某些 nn.Sequential 中)。或许有的读者现在仍然无法理解这样做的意义或者是好处在哪,没关系,具体的使用方法和优势体现将在 定制你的 YOLO11 网络架构(下)中体现,敬请期待。但现在,我们继续来看看这份 YAML 文件中还写了什么。
以 backbone 的前三项为例,内容是:
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]再仔细观察 YOLO11 网络架构图,发现第一个模块叫 Conv,它接受一个 $640\times640\times3$ 的 RGB 图像,小字中写着 k = 3, s = 2,层级为 0。紧接着,Conv 后面的模块又是一个 Conv,只不过输入变为了 ${320}\times{320}\times(min(64,mc)\times{w})$,但 k = 3, s = 2 是一样的,层级为 1。再接着,后面接的模块变为了 C3k2,其输入为 $160\times160\times(min(128,mc)\times{w})$,小字中写着 c3k = False, n = 2 × d, e = 0.25,层级为 2。
对照 backbone 的前三项,有没有发现什么?没错!列表中的 from 参数指定了当前这个模块的输入来自哪个模块的输出,而写个 -1 则代表直接来自“上一个模块”,也就是当前 YAML 文本中前一行所定义的模块(比如 C3k2 的“上一个模块”是层级 1 的 Conv 模块)。repeats 模块则定义了当前这个模块要重复几次,如层级 2 的 C3k2 模块就被要求重复了 2 次(当然,架构图中可以看到还乘了个系数 $d$,当模型尺寸为 n、s 和 m 时取 0.50,那么最后(n、s 和 m 模型中的层级 2 处的)C3k2 模块的重复次数就是 $2\times{0.50}=1$,ultralytics 就靠这个系数来约束模块数量从而控制尺寸和参数量)。最后,对于 args 部分,看名字就知道这部分应该是和模块初始化参数相关的内容。是的,比如层级 1 的 Conv 模块,其 args 是 [128, 3, 2],128 是什么笔者先按下不表,但 3 和 2 应该很容易对应到 k = 3 和 s = 2;又如层级 2 处的 C3k2 模块,其 agrs 是 [256, False, 0.25],又已知架构图中其 c3k = False,且 e = 0.25,自然和 False 与 0.25 挂上了关系。如此看来,短短二三十个字符,就把模型的输入、输出、数量、类型、参数、层级描述得清清楚楚,序列化的架构功不可没。
在闲暇之余,请读者自行探究 yolo11.yaml 以及其它模型的 YAML 配置文件及其网络架构图的联系。在完整熟悉之后,会让您对 YOLO 系列模型的整体定义与结构分布的理解有极大的促进作用 —— 至少不用担心看到 YOLO 模型网络架构图时就会感到迷茫和困惑。
各类 PyTorch 模块的定义
现在,让我们来探索 nn 子模块。
展开 nn 模块以及 nn.modules 模块,不难发现,nn 目录下的文件比较简洁,基本都是以单文件形式存在的(子)模块。
其中,nn 模块下的 autobackend.py 子模块中提供了自动后端推理支持:无论是 .pt、.pth、.onnx 还是 .engine 等格式的模型,在 Ultralytics 框架中都可以直接进行推理 —— 因为 autobackend.py 会自己找合适的推理后端,如 ONNX Runtime。tasks.py 则主要提供了不同视觉任务的基类定义和统一接口:视觉任务有许多种,如分类、目标检测、实例分割和语义分割等,每个类都继承自通用的基类,并实现各自的 forward()、loss()、predict() 方法。text_model.py 则与多模态任务有关:比如通过文本的提示词来分割图像上的特定目标,或者是某个图像中的目标转换为文本化的输出 —— 就像我们使用 ChatGPT、Gemini、Qwen 等多模态大语言模型那样,只不过这里是提供“双模态小模型”的支持罢了(在 text_model.py 中,你甚至可以看到 Ultralytics 官方已经提供了与 CLIP 相关的接口支持)。
而 nn.modules 子模块才是本节的核心所在。有 PyTorch 开发经验或是对 YOLO/Ultralytics 架构比较熟悉的读者可能通过模块命名就一眼就看出来了:activation.py 中定义了激活函数,在 YOLO11 中,这里定义的是 AGLU 函数;block.py 中定义的是各类与特征提取、注意力机制相关的模块,如 SPPF、C3k2 和 C2PSA 等;conv.py 中定义的是各类与下采样、(通道)连接相关的模块,如 Conv、GhostConv、Concat 等;head.py 中定义的是各类检测头模块,如目标检测的 Detect 头,又如实例分割的 Segment 头,还如定向检测的 Pose 头等;transformer.py 中则为 Ultralytics 实现的与 Transformer 架构相关的模块,如 Transformer 编解码器等;最后,utils.py 则提供了一些神经元级的工具函数,如翻转 Sigmoid 激活函数的 inverse_sigmoid() 和用于均值初始化全连接层的 linear_init()。
模块的组装与按任务划分的“引擎单元”
models 子模块中又分别有 6 个子模块,分别是:models.fastsam、models.nas、models.rtdetr、models.sam、models.utils 和 models.yolo。碍于篇幅原因,前 5 个子模块笔者暂不予赘述,重点讲述 models.yolo 子模块。
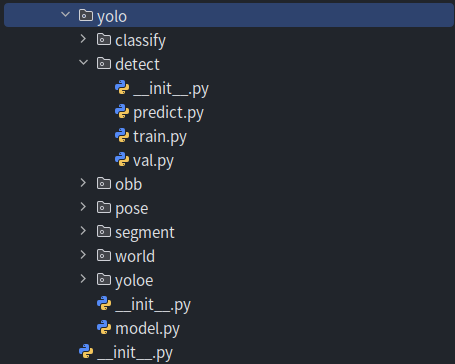
展开 yolo 目录,映入眼帘的是 classify、detect、segment、…、yoloe,似乎与 YOLO 系列的分类、目标检测、实例分割等视觉任务相关。再展开 yolo/detect 目录,又能看见 train.py、val.py 与 predict.py,光看名字就能看出是与训练、验证和推理相关的模块。所以不难看出,models 子模块中的各个子模块都基本按照计算机视觉模型 -(按视觉任务划分的子模型)- 按阶段任务划分的模块这样的布局,即所有独立模型单元的阶段任务实现都在 models 当中了,最后被 engine 子模块封装。
但 models 中有一个独立的 model.py,来看看里面有什么:
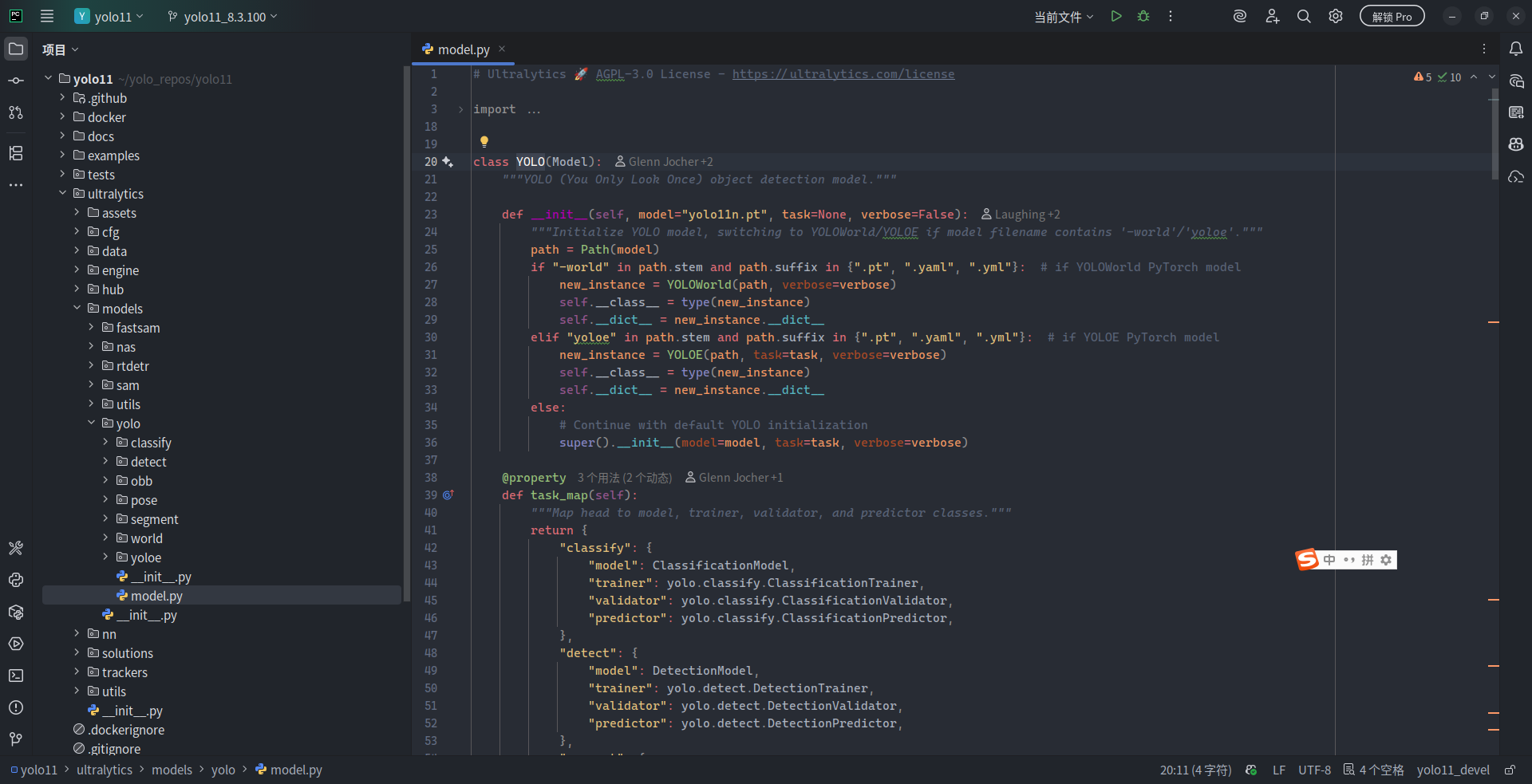
如上图所示,model.py 的第 20 行处出现了一个 YOLO 类型的定义。不难看出,model.py 用于对这些模型及任务实现了抽象封装,把不同视觉任务的模型(分类、目标检测、实例分割等)统一用一个 YOLO 类型进行了抽象。当然,YOLOE 和 YOLO-World 也有各自的抽象定义,类型分别为 YOLOE 和 YOLOWorld。
再仔细观察,发现 YOLO 类型继承自 ultralytics.engine.model.Model 类型。跳转到其定义,发现 ultralytics.engine.model.Model 直接继承自了 torch.nn.Module:
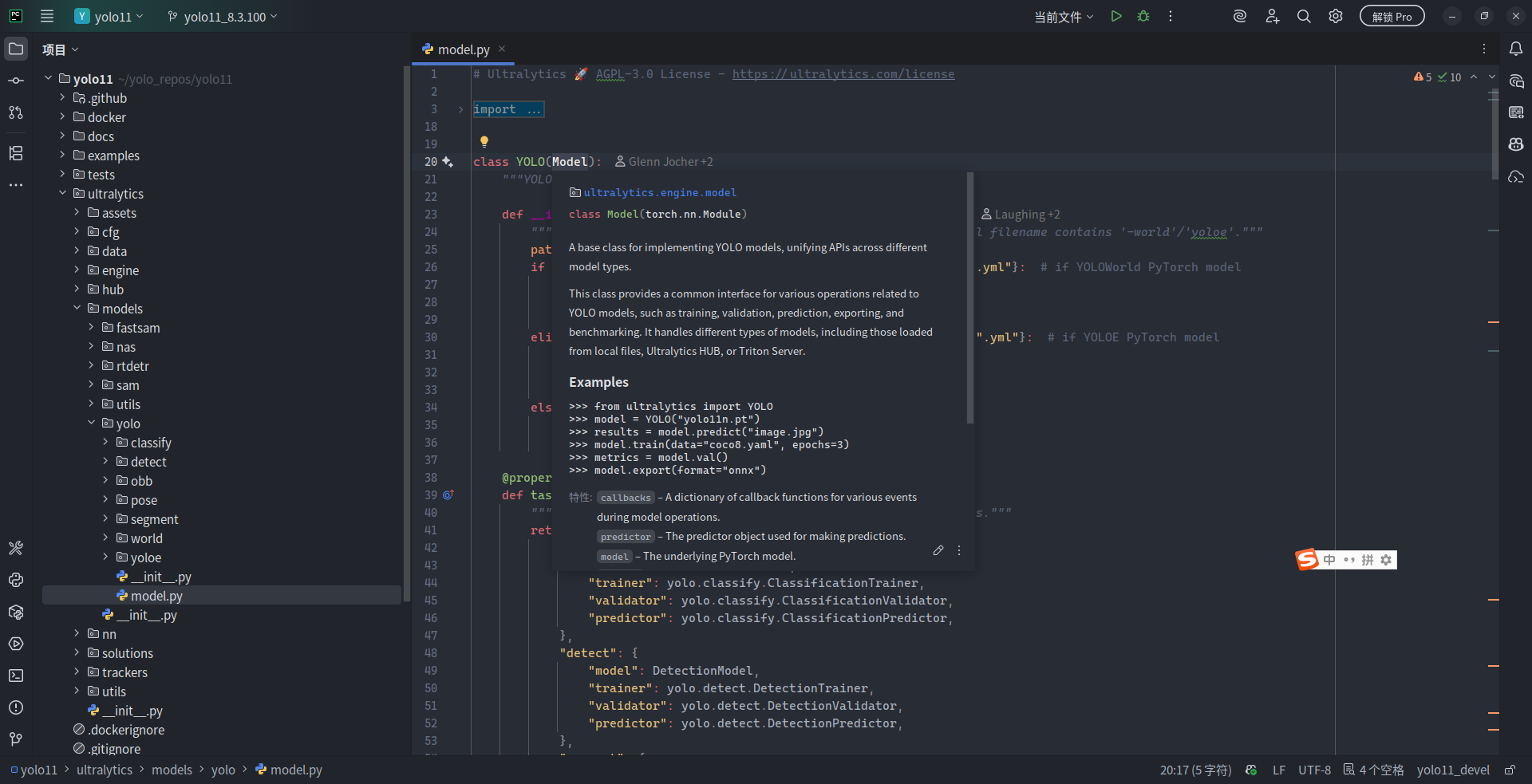
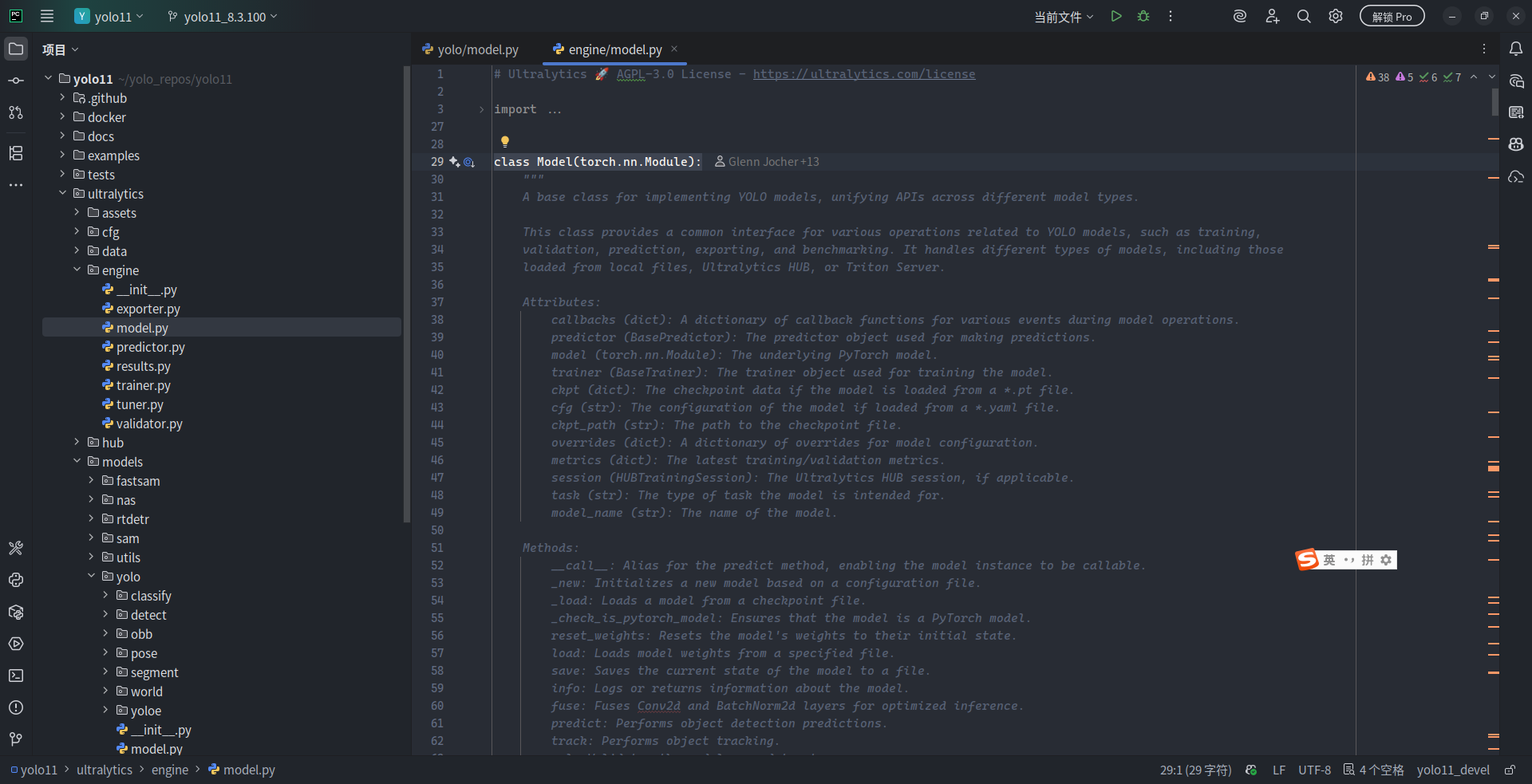
向下翻到 143 行位置,看到了这么一行注释:# Load or create new YOLO model。也就是说,当我们在 Python 中使用 .yaml 文件来加载模型时,在构造 ultralytics.YOLO 类型时,其实是被 ultralytics.engine.model.Model 基类自动处理了模型的构建过程:使用 YAML/YML 时调用 _new() 方法来“对着图纸搭积木”,使用 .pt/.onnx 等模型时就调用 _load() 方法直接加载调用。
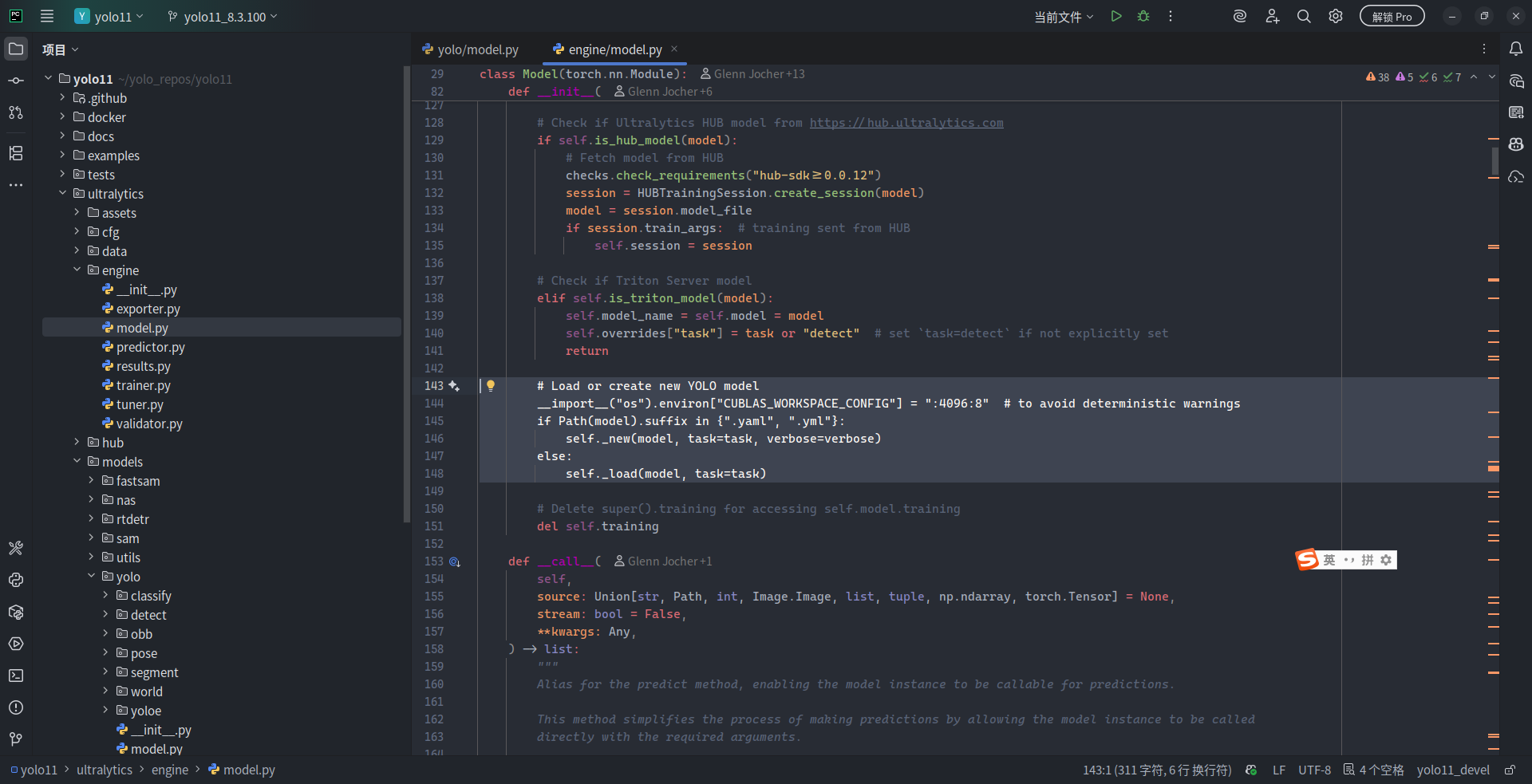
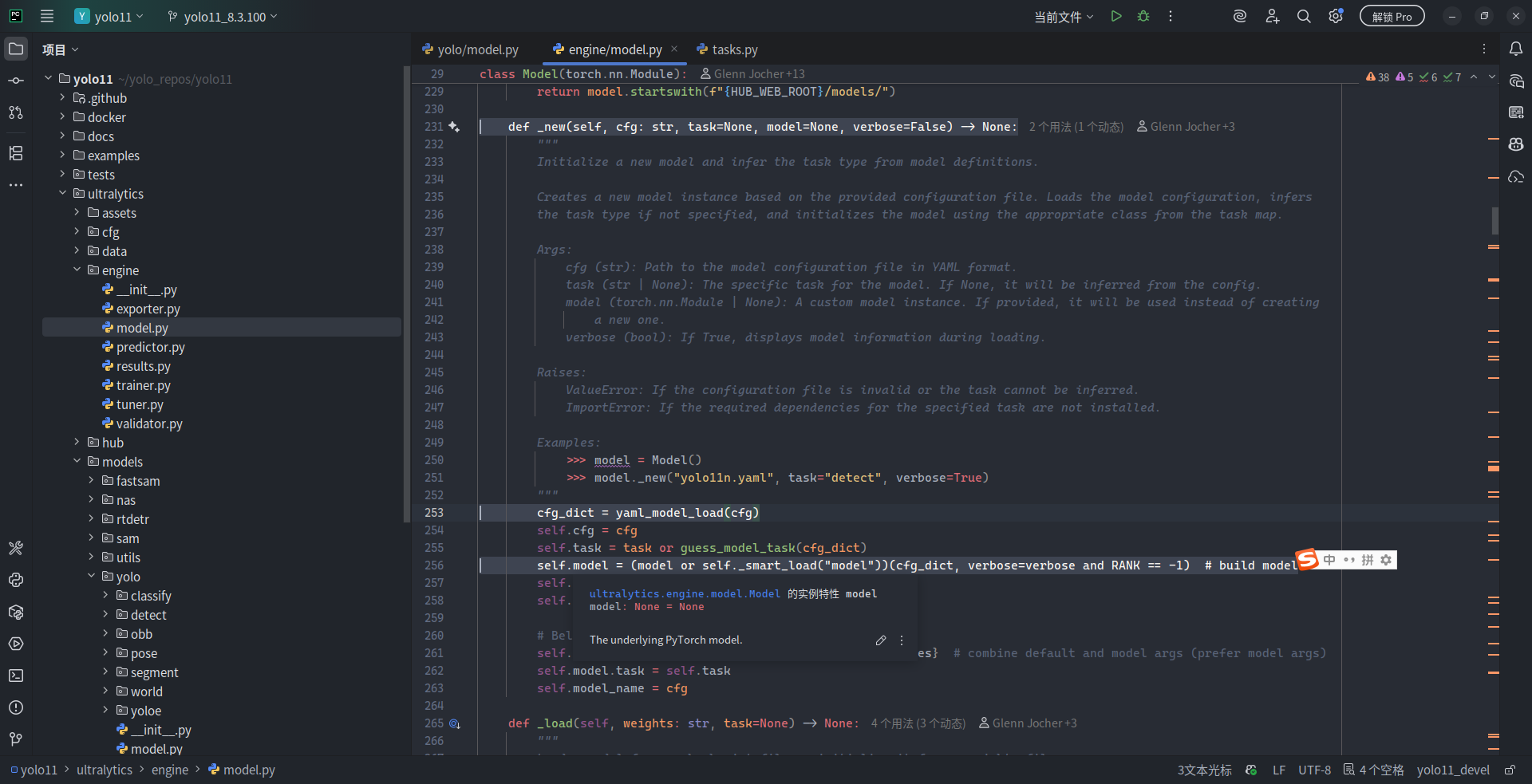
再跳转到 _new() 方法的定义,可以看到具体的构建方式:先将 YAML 中的内容转为 Python 字典,然后根据 [from, repeats, module, args] 中的内容逐层实例化并组装成 torch.nn.Sequential,最终形成整个模型。碍于篇幅限制,笔者也不再继续深入其调用链条,完整剖析模型的构建过程了。这一部分内容只是想告诉各位读者的是,前面看到的 YAML 文本的模型是通过什么方式变成 PyTorch 模型的,这些实现部分存在于 ultralytics 的哪些子模块中,大致的调用链条是什么。Ultralytics 不是一个简单的框架,其中有相当多的内容是为了简化计算机视觉深度学习技术的上手门槛和使用难度而做的工程化构建,绝非只是单纯地将 PyTorch 模块进行了封装成一系列 (YOLO) 模型成品就完事了这么简单。
Ultralytics 框架的工具箱
最后要介绍的就是 utils 子模块了。utils 相对于其它比较 “Deep Learning” 的部分看起来比较不起眼,但确实是 Ultralytics 框架的重中之重。不夸张地说,没有 utils,资源配置和缓冲区管理会变得棘手,数据集的前处理可能会严重出错,训练、验证和推理可能都无法运行……笔者粗略列举了 utils 中部分子模块的作用:
autobatch.py: 自动估算 YOLO 训练时的最佳 batch size,使其合理利用 CUDA 显存资源;benchmarks.py: 用于对不同格式的 YOLO 模型进行速度和精度基准测试,支持多种导出格式(如.pt、.onnx等);checks.py: 包含环境、依赖、模型等各类检查工具,确保运行环境和依赖项的正确性;downloads.py: 负责模型、数据等资源的下载、缓存和管理,支持多线程下载和断点续传;errors.py: 自定义异常类,主要用于模型下载、加载等过程中的错误处理和提示;files.py: 文件和目录操作相关工具,如临时切换工作目录、文件查找等;loss.py: 各类损失函数的实现,包括目标检测、分割等任务常用的损失;metrics.py: 各类模型评估指标的实现,如 $P$、$R$、$mAP$、$IoU$ 等;plotting.py: 可视化相关工具,如绘制检测结果、损失曲线等;torch_utils.py: 与PyTorch 相关的通用工具函数,如自动混合精度、模型分析等;triton.py: NVIDIA Triton 推理相关工具,支持高性能推理部署;tuner.py: 超参数自动调优相关工具。
当然,还有 utils.callbacks 子模块,顾名思义,与回调处理有关。由于大部分人应该不会专门使用或者定制 ultralytics 中的回调处理部分,因此笔者也同样不予赘述,留给各位读者自行查看和探究。
上述这些模块,基本上都是为了优化使用体验、增强易用性而存在的,比如 downloads.py,可以自动从 GitHub 上下载 yolo11s.pt;又比如 plotting.py,我们常常看见的训练/验证指标示意图就是由这个子模块所完成的。因此,utils 也成为了 Ultralytics 的工程基建层中各类 bug 的藏匿点,大部分 GitHub PR 都来自对 utils 中的 bug 修复。因此,当您的 Ultralytics 框架在工程层面出现明显的非预期行为时,请优先考虑是否是 utils 中某处代码逻辑存在问题,然后可以尝试修复,甚至提交 PR 给 Ultralytics 仓库。
本文总结
本文从 Ultralytics 8.3(YOLO11)的源码构造切入,围绕 ultralytics.cfg、ultralytics.nn、ultralytics.models、ultralytics.utils 四个关键模块,梳理了模型配置、模块定义、任务封装与引擎组网的主线,并说明 yolo11.yaml 如何被表示并被解析为可训练的 PyTorch 模型。本文作为该系列博客的“(上)”篇,讲述了如何初步看懂 Ultralytics 框架,为修改网络架构做好准备。“(下)”篇则将进入定制实战,以增添 CCAM 注意力模块为例,演示从结构改动、配置联动到训练验证的关键步骤。欢迎各位在评论区分享更多您对 Ultralytics 框架的了解与想法。受限于笔者的水平,也欢迎您提出对本文的建议和意见,笔者将尽可能地修改并优化。敬请期待“(下)”篇:定制你的 YOLO11 网络架构(下)。